

Zero Lines of Python
What happened when I replaced my API with a prompt

I wanted help keeping a dev journal.
I use Claude Code for most of my development on research projects now. The side effect: I accomplish more in a week than I can remember. That sounds like a humble brag. It isn’t. It’s a problem. When Friday arrives and I try to reflect on what happened, I’m doing archaeology. Manual journaling doesn’t work for me. By the time I remember to write things down, the context has evaporated.
Here’s what I realized: Claude Code already knows what I did. Every session is logged. Every tool call, every file touched, every todo created. The data exists in ~/.claude/. It’s just not exposed in a way I can use.
So I built an API. About 2,800 lines of Python. Then I tried the same task with just a system prompt and Claude Code’s existing tools. The results were comparable.
This is a story about that discovery, and what it might mean for how we build with AI.
Context: this is a personal productivity experiment. Your workflow will shape how these patterns apply.
Mapping the Data
I started by mapping what’s actually in ~/.claude/. Turns out it’s a treasure trove:
Session transcripts (~/.claude/projects/[project-id]/*.jsonl): every conversation, preserved with timestamps, tool calls, and reasoning.
File history (~/.claude/file-history/[session-uuid]/): versioned backups of everything Claude touched (used for rollbacks).
Todos (~/.claude/todos/): task lists from each session with completion states.
Stats (~/.claude/stats-cache.json): aggregated metrics like message counts, session durations, and model usage.
Each session has a UUID that correlates across all these directories. Cross-reference by UUID, and you can reconstruct exactly what happened.
I documented my current understanding in detail, covering file formats, message types, and correlation patterns: Gist link
This research phase turned out to be the most valuable part of the entire project. But I didn’t know that yet.
Building the Abstraction
With the data structures mapped, I did what developers do: I built an abstraction layer.
A FastAPI server that reads from ~/.claude/, applies the research domain logic, and exposes REST endpoints:
GET /activity/summary: activity across date rangesGET /projects/{id}/sessions: sessions for a projectGET /sessions/{id}/messages: full conversationGET /sessions/{id}/todos: correlated task lists
Then I built a Claude Code Skill: a system prompt that knew how to call this API via a Python proxy script. The proxy was necessary because Claude Code’s sandbox restricts network access. [Skill system prompt gist →]
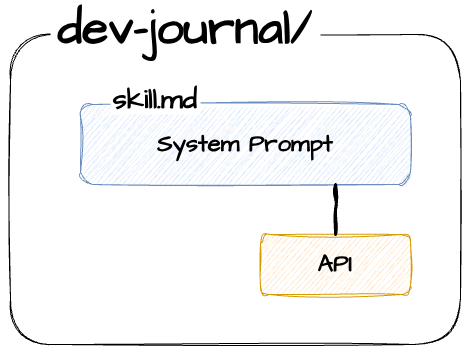
With the Skill installed I asked Claude Code for a dev journal of the last three days. Here’s what I got:
Gist link →

Decent output. It gave me a structured, day-by-day breakdown with project headers and concrete deliverables. The format was clean, scannable, and organized by what mattered. It worked.
But based on my experience with LLMs and Claude Code specifically, my instincts told me to question the approach. I’d been here before: building elaborate scaffolding when the model might handle the task with less structure. Was the API necessary, or was I over-engineering?
The Experiment
The skill I built had two parts: the system prompt (instructions for how to journal) and the API proxy (access to the data). What if I stripped the API and just... gave Claude Code the context?
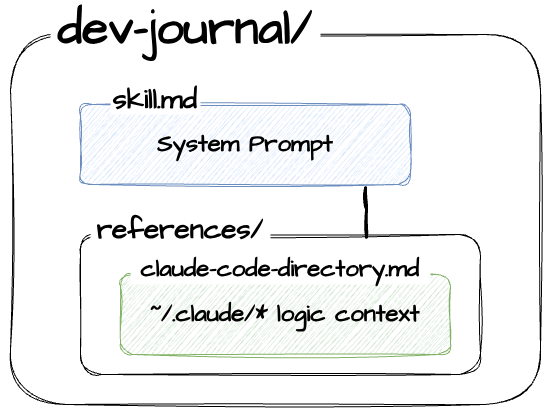
I took my research doc (the one mapping ~/.claude/ data structures) and added it to Claude Code’s system prompt used in the Skill. No API. No proxy. Just: “Here’s how the data is organized. Figure out what I did last week.”
Claude Code already has Read, Glob, and Grep tools. It can navigate filesystems. I ran the experiment.
The Results
It was more than enough.
The system-prompt-only version produced this:
The quality was comparable, arguably better in places. Claude Code, armed with just its base tools and an enhanced system prompt, surfaced as much context as my API had. It navigated the ~/.claude/ directory structure, parsed the JSONL files, correlated sessions by UUID, and synthesized a coherent journal. No custom endpoints required.
Two comparable results. One required 2,800 lines of Python. One required zero.
What This Means
It’s a strange result to sit with. The API works. I just didn’t need it yet.
To be transparent: my API is a POC and probably has logic errors. The endpoints could be better organized. But that’s beside the point. Claude Code reached POC-quality output, maybe even MVP, without the investment of a custom API.
Why did this work? Claude Code already had the primitives it needed: Read, Glob, Grep. These are tools for navigating filesystems and parsing text. The ~/.claude/ data is just JSON and JSONL files. The harness already had what it needed; I just hadn’t given it the context to use those tools effectively.
The research was the work. Mapping data structures and understanding correlation patterns turned out to be the valuable artifact. The API was scaffolding I could have skipped, for now. The instinct to build wasn’t wrong, just early. Context, delivered through a system prompt, was enough.
This might generalize beyond Claude Code. What is Claude Code? A harness around an LLM: tools and permissions wrapped around Claude. Any LLM-based system with the right primitives might exhibit this same behavior. Cursor, Windsurf, Aider, custom agent frameworks: if the primitives exist, context might be enough. That’s a hypothesis worth testing.
A heuristic worth trying: POC with prompts first. Start with context. Let the agent figure out the workflow. Reach for explicit code when you need determinism, efficiency, or guarantees the agent can’t provide. Not before.
This connects to something I wrote about in Implicit Memory Systems for LLMs: “We implement the hooks; Claude provides the intelligence.” That pattern showed up again here, but inverted. I implemented less, and the intelligence filled the gap.
What’s Next
Much of my current research focuses on an architectural approach where the agent is the true orchestrator, not just a component you call. I’m calling this “Agent Native Architecture.” What does it look like to design systems around that premise?
The API work waits. When I need speed, caching, or deterministic output, it’s ready. But I won’t know until I’ve pushed the prompt-first approach further.
More experimentation coming.
What Came Out of This
If you want to try this yourself:
The Dev Journal Skill: The prompt-first version that worked surprisingly well. Available in the AlteredCraft plugin marketplace →
Claude Explorer: The API + React UI for structured access to your ~/.claude/ data. Still WIP, but functional (more validation testing needed). GitHub repo →
The research doc: Full breakdown of my current understanding of the ~/.claude/ directory
data structures (also bundled in the Dev Journal Skill). Gist link.
The data is already there. Sometimes the smartest thing you can build is context.
Two thoughts:
- Time to build an aggregator for Claude Code enabled teams that just generates the unimportant updates of Stand-ups into pre-reads, so the team can cut to blockers/important shit?
- Do you think there's a way to analyze productivity with this data?