

Weekly Review: The Workbench
A quiet model week with the action at the workbench: CLIs, completion commands, middleware, plan reviewers, terminals, and hardware-aware model pickers

Welcome to this week’s Altered Craft AI review for developers. Thanks for showing up again. Where last week’s edition mapped the production stack around the model, this week the gravity sat one layer closer to the developer: the workbench. A /goal command in Claude Code, composable middleware, a plan annotator, a new CLI agent, a macOS terminal built for coding agents, and a smarter way to pick a local model. The editorials run alongside, asking what code, language, interaction, and creativity look like once the bench gets this capable.
TUTORIALS & CASE STUDIES
These pieces sharpen the workbench: how to scaffold Claude for a large codebase, which prompt techniques carry the most weight, how to wire a repair loop, and how to isolate one when it runs unattended.
Scaling Claude Code: Patterns for Large Codebases
Estimated read time: 12 min
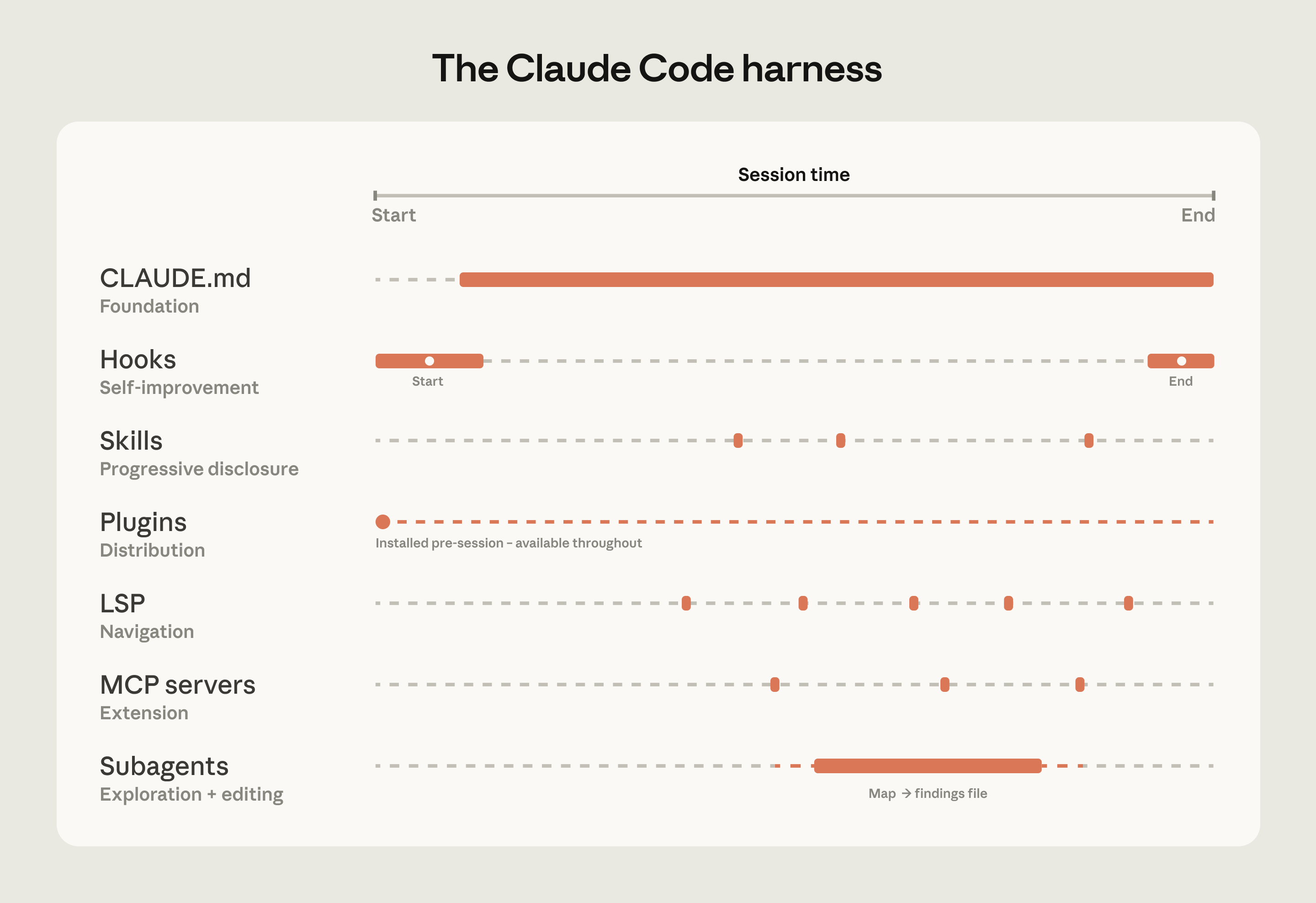
Anthropic shares field-tested patterns for deploying Claude Code in monorepos and legacy systems. The piece argues the harness matters as much as the model, detailing how CLAUDE.md, hooks, skills, plugins, LSP, and MCP servers make agentic search reliable at scale.
Where to invest: Build out layered CLAUDE.md files, scoped commands, and LSP integration before reaching for fancier extensions. Codebase legibility determines how well Claude actually performs.
Claude’s Prompt Engineering Guide, Refreshed
Estimated read time: 9 min
Zooming in from harness to technique, Anthropic’s refreshed overview ranks prompt techniques by impact: clarity, examples, chain-of-thought, XML tags, roles, and prefilling. It frames prompt engineering as faster and cheaper than fine-tuning, with concrete patterns developers can apply when building on Claude.
Why this matters: Before reaching for fine-tuning or RAG, work through the prompt engineering ladder. Clarity, examples, structure, and chain-of-thought often close the gap on their own.
Building Iterative Repair Loops with Codex
Estimated read time: 9 min

From prompting patterns to loop patterns, OpenAI’s cookbook walkthrough shows how to build iterative repair loops where Codex diagnoses and fixes its own failures by feeding test results back into the model until the agent converges on a working solution.
Key point: Treat Codex less like autocomplete and more like a closed-loop system where test output drives convergence.
Building a Sandbox for Codex on Windows
Estimated read time: 14 min

When loops run unattended, isolation becomes load-bearing. An OpenAI engineer details why existing Windows isolation tools fell short for Codex and how the team built one using synthetic SIDs and write-restricted tokens, eventually trading their no-elevation goal for real firewall enforcement via dedicated local users.
Worth noting: When OS primitives don’t fit your agent’s threat model, expect to trade simplicity for real isolation, and document the tradeoffs honestly.
TOOLS
This is where the week actually lived. New entries land on the workbench across nearly every slot: a completion-loop command, composable middleware, a plan annotator, a new CLI agent, a macOS terminal for coding agents, and a hardware-aware model picker.
Claude Code’s /goal Command: Removing the Human Bottleneck in Agentic Sessions
Estimated read time: 8 min
Continuing our coverage of /goal as a built-in Ralph loop[1] from last week, Claude Code adds its own /goal command. In long agentic coding sessions, the bottleneck isn’t the model, it’s the human pressing enter. /goal defines a completion condition once, then loops until an evaluator model confirms it’s met.
The opportunity: Write /goal conditions around observable output (passing tests, clean lint, verifiable diffs), never vague end states like “production-ready.”
[1] Codex CLI Adds /goal: A Built-In Ralph Loop
Genkit Middleware: Composable Hooks for Production Agentic Apps
Estimated read time: 5 min
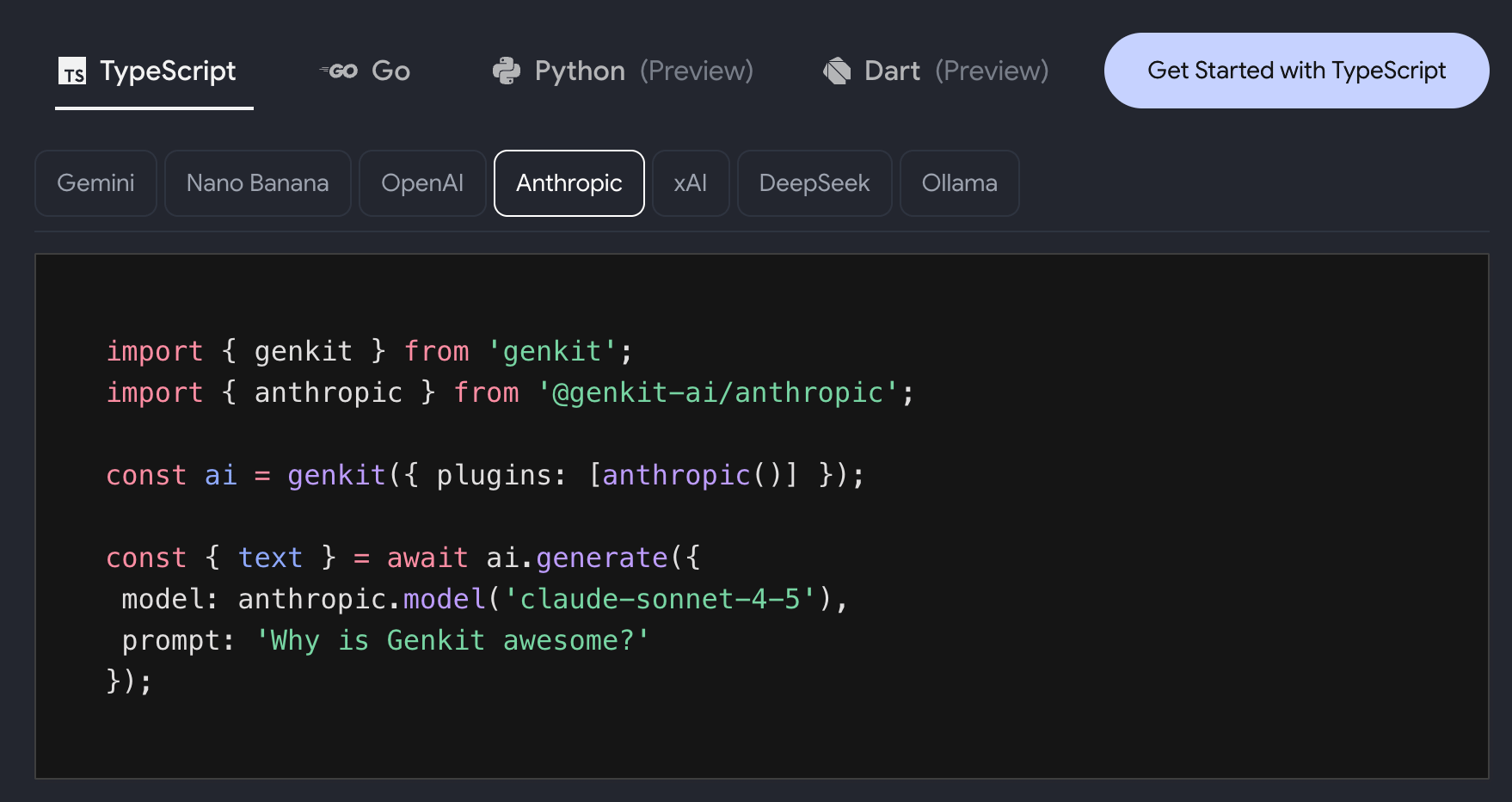
Wrapping safety around those loops, Google’s Genkit adds composable middleware hooks that intercept the tool loop at generate, model, and tool layers. Pre-built options cover retries, fallbacks, human-in-the-loop approval, and scoped filesystem access. Custom middleware takes around 20 lines, in TypeScript, Go, and Dart.
What this enables: Stop encoding reliability and safety rules in every prompt. Wrap them as middleware once, then compose them across your agentic stack.
Plannotator: Visual Plan and Code Review for AI Coding Agents
Estimated read time: 4 min

Adding a human review step between plan and implementation, Plannotator brings a visual annotation layer for AI agent plans and code diffs, letting developers approve or mark up agent output before code is written. It integrates with Claude Code, Copilot CLI, Gemini CLI, OpenCode, Pi, and Codex.
What’s interesting: A visual review step between planning and implementation can catch issues that text-only approval flows tend to miss.
xAI Launches Grok Build: A New CLI Coding Agent
Estimated read time: 2 min
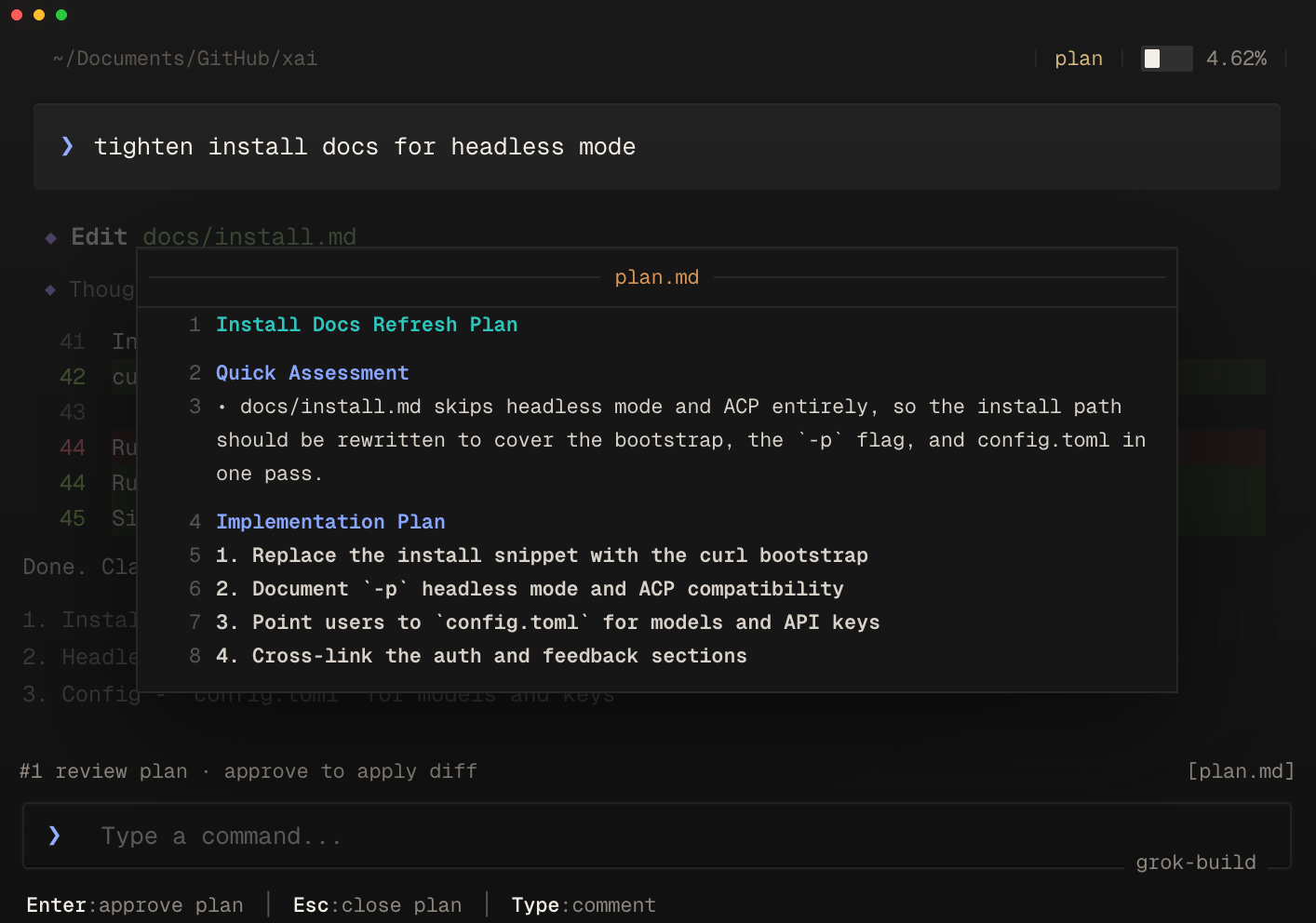
In more news on terminal coding agents, xAI enters the space with Grok Build, an early beta CLI for SuperGrok Heavy. It offers plan-mode review, parallel subagents across git worktrees, headless scripting, and out-of-the-box support for AGENTS.md and MCP servers.
cmux: A Native macOS Terminal Built for Coding Agents
Estimated read time: 2 min
Also in the workspace layer for those agents, cmux is a free, native macOS terminal built on libghostty for developers running Claude Code, Codex, and Aider. It offers vertical tabs, split panes, and notification rings when processes need attention, replacing tmux config files with a GUI workflow.
The context: If you juggle multiple terminal-based coding agents on macOS, cmux gives you GUI-level workspace management without tmux’s configuration overhead.
whichllm: Stop Guessing Which Local LLM Actually Fits Your Rig
Estimated read time: 8 min
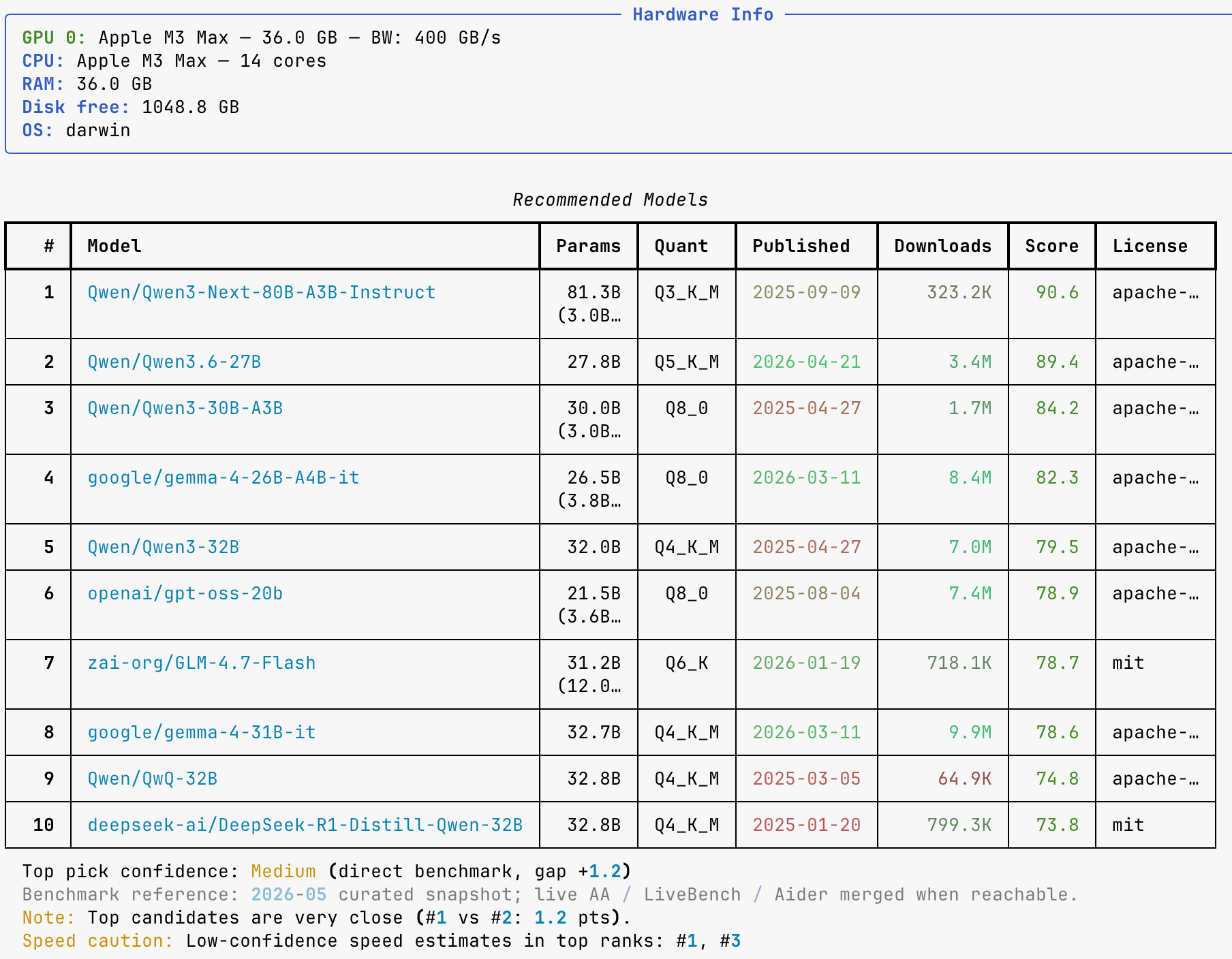
Closing the tools section on model selection, whichllm is a CLI that auto-detects your hardware and ranks HuggingFace models using evidence-based scoring instead of size heuristics. Merged LiveBench, Aider, and Arena ELO data with confidence dampening lets a smaller, newer model outrank a bigger stale one.
Practical tip: Before downloading another local model, run whichllm to see which one your hardware can actually run well, not just fit.
NEWS & EDITORIALS
These pieces ask the bigger questions a more capable workbench provokes: what code, language, interaction, and creativity really mean once the typing itself is the easy part.
What Is Code? Rethinking Value in the Age of LLMs
Estimated read time: 11 min
Continuing our coverage of Lars Faye’s case against outsourcing reasoning[2] from last week, Unmesh Joshi argues that as LLMs commoditize code production, the enduring value lies in code as a conceptual model of the domain. He explores vocabulary, bounded contexts, and warns that generated code can outpace team understanding.
The principle: Treat coding as vocabulary building, not text production, because strong abstractions are what make both your team and your LLMs effective.
If AI Writes Your Code, Why Use Python?
Estimated read time: 5 min
Extending the question of what coding becomes, Mitchem poses a pointed challenge: Python’s appeal has been readability, but when AI generates the code, runtime characteristics matter more than syntactic friendliness. The piece invites developers to reconsider language choice on performance grounds.
The takeaway: When AI handles the typing, the criteria for picking a language shift toward what runs well, not what reads easily.
Interaction Models: When AI Stops Waiting for Its Turn
Estimated read time: 11 min
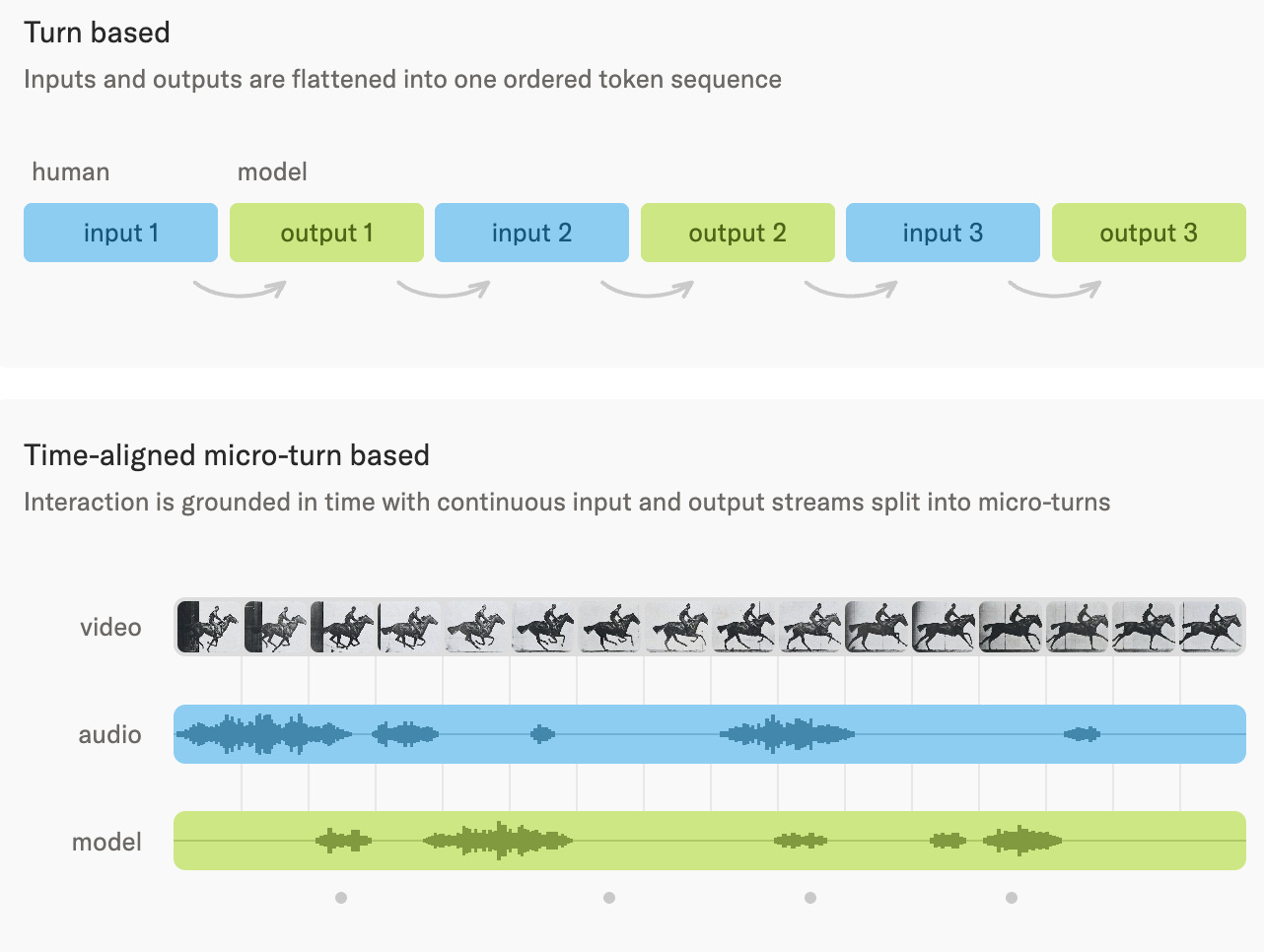
Shifting from code to how we interact with the systems writing it, Thinking Machines previews a model where interactivity is baked in, not bolted on. Using 200ms micro-turns across audio, video, and text, it perceives and responds continuously, with a background model handling deeper reasoning.
Heads up: If interaction is part of the model rather than the harness, scaling intelligence also scales how well humans can stay in the loop.
The Subjective Wall: Why AI Creativity May Require Real Feeling
Estimated read time: 5 min
Closing on the philosophical edge, Daniel Miessler argues human creativity runs on intrinsic drives and subjective experience, suggesting AI hits a subjective wall when faking what it cannot feel. Truly creative AI may require giving machines real desires and pain, raising hard ethical questions.
The counterpoint: Before chasing more “creative” AI, consider whether the path forward requires building systems that can suffer, and whether that’s a responsibility worth taking on.
That’s the week. Quiet at the model layer, busy at the workbench. See you next Monday.