

Weekly Review: The Outer Loop
When agents start closing their own loop: the guardrails that let them self-verify, the open models racing to orchestrate, and the work that moves up the stack to you

Altered Craft
Welcome back to Altered Craft’s weekly AI review for developers, and thank you for starting your week with us. Last week we followed the money; this week we follow the loop. Agents are reaching deeper into their own cycle of writing and checking, from self-validating guardrails to workflows that fan across hundreds of subagents, with Claude now authoring most of its own merged code. As that inner loop closes, the work that stays yours moves outward: setting the guardrails, directing the fleet, and choosing which problems matter.
TUTORIALS & CASE STUDIES
We open with the principle that pushes you out of the inner loop, then turn to two production realities: keeping RAG costs in check and running frontier models inside your own cloud perimeter.
Backpressure Is All You Need: Stop Being Your Agent’s Bottleneck
Estimated read time: 11 min

Building on our coverage of Anthropic’s point that verification is now the bottleneck[1], Lucas da Costa argues humans have become the default backpressure in AI coding loops, shuttling feedback between agents and bots. His fix: build automated guardrails (tests, types, benchmarks, review agents) that force the LLM to validate its own work first.
The takeaway: If you are manually correcting your coding agent every cycle, you are not delegating, you are an expensive clipboard between two machines.
[1] Using LLMs to Secure Source Code: A Six-Step Loop
RAG Is Burning Money: Building a Cost Control Layer
Estimated read time: 14 min

Once the agent is checking its own work, the next thing to watch is the bill. A working RAG pipeline can drain budgets through over-fetched context, uncached repeats, and oversized models on trivial queries. This walkthrough builds a four-layer cost control system with semantic caching, routing, and token budgeting, achieving up to 85.8% cost reduction.
Worth noting: Treat RAG cost as a separate failure domain from quality, and instrument routing and caching before scaling traffic.
Running OpenAI Models on Amazon Bedrock: A Production Cookbook
Estimated read time: 12 min
Staying with production concerns, OpenAI’s cookbook walks through running GPT-5 models on Amazon Bedrock via an OpenAI-compatible Responses API, using a fictional retailer support workflow to cover structured outputs, function tools, PDF inputs, prompt caching, background mode, stateful conversations, and operational smoke checks.
What this enables: If you need OpenAI models inside your AWS perimeter, Bedrock now exposes the full Responses API surface with minimal code changes from a standard OpenAI SDK setup.
TOOLS
The model releases cluster by job this week: open-weight coding and multimodal models, an orchestrator built for long-running agents, the workflow layer that fans work across hundreds of subagents, and a scanner to keep the skills they use safe.
MiniMax M3: An Open-Weight Model Targeting Frontier Coding and Agentic Work
Estimated read time: 11 min
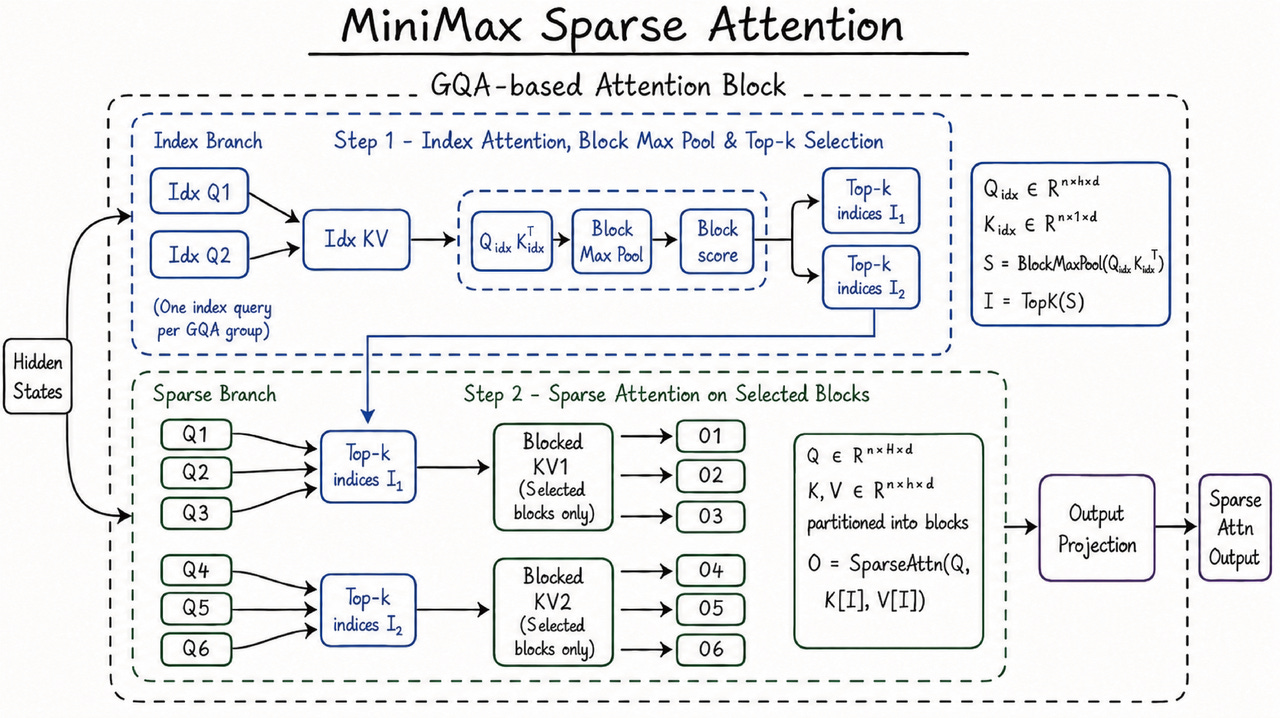
MiniMax releases M3, an open-weight model with 1M context and frontier coding scores powered by a new sparse attention architecture called MSA. Tests include a 24-hour autonomous CUDA kernel run that lifted Hopper FP8 utilization from 7.6% to 71.3%.
The signal: Long-horizon agentic coding is increasingly bottlenecked by attention architecture, not model size, and open-weight options are starting to close the gap with closed frontier models.
Microsoft’s MAI-Code-1-Flash: Trained Inside the Copilot Harness
Estimated read time: 3 min
 outperforms Claude Haiku 4.5 (orange) across benchmarks, with higher pass rates and lower token use in the highlighted “Ideal Zone.”.")
Another approach to coding models, Microsoft’s MAI-Code-1-Flash was trained directly inside GitHub Copilot’s production harness rather than tuned for benchmarks. Adaptive solution length control reportedly cuts token use by up to 60% on harder problems while outperforming Claude Haiku 4.5 across four SWE-Bench evaluations.
Why this matters: Coding models trained inside the actual production harness tend to translate offline gains into real developer workflows more reliably than benchmark-optimized alternatives.
Gemma 4 12B Ships with Encoder-Free Multimodal Architecture
Estimated read time: 7 min

Shifting from coding to multimodal, Google releases Gemma 4 12B, a dense model with an encoder-free architecture that feeds vision and audio straight into the LLM backbone. It runs on 16GB VRAM, supports native audio, and ships with macOS apps and a local OpenAI-compatible server.
The opportunity: Developers can now run a single multimodal model locally that handles text, vision, and audio without juggling separate encoders or fine-tuning pipelines.
NVIDIA Nemotron 3 Ultra: Built for Long-Running Agents
Estimated read time: 9 min
Moving from models to orchestration, NVIDIA releases Nemotron 3 Ultra, a 550B-parameter MoE model designed for frontier reasoning and orchestration in agentic systems. It claims 5x higher throughput than peers and up to 30% lower cost per agent task, shipping fully open under OpenMDW-1.1.
The pattern: If you’re building multi-turn agents, pairing a frontier orchestrator with efficient execution models is becoming the dominant pattern, and Nemotron 3 Ultra is now a credible open option for the orchestrator role.
Claude Code Gets Dynamic Workflows: Hundreds of Parallel Subagents in One Session
Estimated read time: 5 min
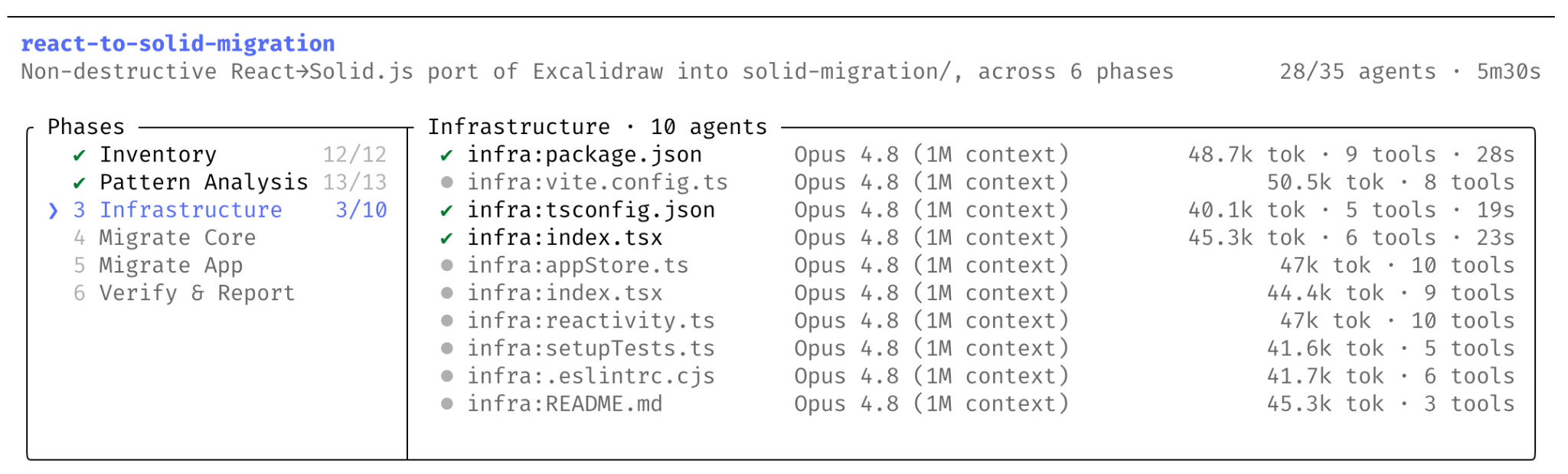
Taking orchestration further, Anthropic’s 4.8 release brings dynamic workflows to Claude Code, where Claude writes orchestration scripts fanning work across hundreds of parallel subagents with adversarial verification. The lead example: Jarred Sumner’s port of Bun from Zig to Rust, 750,000 lines, eleven days.
Key point: When a task is too big for a single agent pass, dynamic workflows let Claude plan, parallelize, and self-verify across hundreds of subagents, but expect significantly higher token usage.
SkillSpector: NVIDIA’s Security Scanner for AI Agent Skills
Estimated read time: 9 min
To keep all this safe, NVIDIA’s open-source SkillSpector vets AI agent skills for Claude Code, Codex CLI, and Gemini CLI, combining static analysis with optional LLM evaluation across 64 vulnerability patterns in 16 categories. It produces a 0-100 risk score and SARIF output for CI/CD.
The principle: Treat third-party agent skills like any other untrusted dependency, and scan them before installation rather than granting implicit trust.
NEWS & EDITORIALS
The editorials trace where the human role is heading: from typing to describing, from writing code to directing it, then the market structure underneath, and a closing reminder to protect the thinking the agents can’t do for you.
The Speed of Prototyping in the Age of AI
Estimated read time: 7 min
Daryl Cecile reflects on a rough 4x speedup from AI agents, but argues the more important change is the shift toward describing systems before building them, which sharpens delegation and expands what work he can realistically take on.
What’s interesting: When agents handle the typing, the engineering skill that matters most is clearly describing what success looks like, so deliberately protect time for hands-on work to keep your instincts sharp.
Running an AI-Native Engineering Org: Lessons from the Claude Code Team
Estimated read time: 9 min
In more news on how the work itself is changing, Anthropic’s Claude Code team lead shares how agentic coding reshaped their workflows, from six-month roadmaps to just-in-time planning. The piece covers shifts in code review, context gathering, and team makeup as bottlenecks move from writing code to verifying it.
Try this: Pick your noisiest engineering workflow and ask whether it still serves its purpose, or whether it can be automated or dropped entirely.
When AI Starts Building AI: Inside Anthropic’s Self-Improvement Curve
Estimated read time: 14 min
Following our look at why Claude is not your architect[2] from last week, Anthropic shares internal data: Claude authors 80%+ of merged code, and engineers ship 8x more per quarter than in 2024. The piece traces the path toward recursive self-improvement, while noting Claude still struggles to choose which problems matter.
The shift: The role of a senior engineer is moving from writing code to directing, reviewing, and choosing which problems are worth solving at all.
[2] Claude Is Not Your Architect
Open and Closed Models Are on Different Exponentials
Estimated read time: 8 min
Building on our coverage of Max Trivedi’s case that open models cap frontier pricing[3] from last week, Nathan Lambert argues open and closed AI models run on different economic exponentials. Closed labs capture premium margins through integrated coding agents, while open models diffuse across enterprises at commodity pricing. Both ecosystems grow, but their timelines look nothing alike.
What this means: If your work depends on coding agents, expect to keep paying premium prices for frontier closed models while open models quietly win the long tail of enterprise deployments.
[3] When Outsourcing + Local AI Undercuts Frontier Labs
Anthropic Files Confidential S-1 for Proposed IPO
Estimated read time: 1 min
On the business side, Anthropic has confidentially submitted a draft S-1 to the SEC, opening the option to go public pending review. The filing follows a $65B Series H at a $965B post-money valuation, signaling a potential shift toward public markets.
Worth watching: If Anthropic goes public, the tools developers depend on start answering to quarterly earnings cycles, so watch how that shapes Claude’s roadmap and pricing.
The AI Treadmill: When Staying Current Becomes Its Own Trap
Estimated read time: 8 min
Closing on the human cost, Deb Liu reflects on the quiet panic beneath San Francisco’s AI enthusiasm, where even experts feel perpetually behind. She argues efficiency gains often just refill themselves with more motion, and protecting space to think matters more than chasing every tool.
Key point: Going deep on one tool that changes how you work beats sampling ten you’ll abandon, and the pauses you protect are where your best thinking happens.
That’s the week. The throughline: as agents close the inner loop of building and verifying, your leverage moves to the outer one, the guardrails you set, the fleets you direct, and the problems you choose to point them at. See you next Monday.