

Weekly Review: The Cost of Capable
What changes once coding agents reliably work: the economics of capability, the ceiling open models set, and the judgment that stays yours

Welcome to Altered Craft’s weekly AI review for developers, and thanks for spending part of your Monday here. Last week we marked the capability threshold; this week the questions turn economic. Simon Willison calls April 2026 the moment coding agents found product-market fit, even as open and specialized models put a ceiling under frontier pricing. The tutorials and tools cover building, securing, and harnessing agents, while the editorials weigh what capability now costs and what judgment stays yours.
TUTORIALS & CASE STUDIES
This section runs from hands-on to honest: build your first agent, master the Claude Code harness, point it at real security work, then see where agents quietly fall short on interpretive tasks. We close on how far open models trail the frontier.
Building Your First AI Agent in Python: A Beginner’s Walkthrough
Estimated read time: 9 min
This beginner tutorial walks through building a working AI agent in Python from zero: PyCharm setup, securing API keys with dotenv, connecting to OpenRouter’s free LLM gateway, and constructing a chat loop with the OpenAI client library.
The takeaway: You can stand up a functional agent in under an hour by pairing OpenRouter’s free gateway with the OpenAI Python client and a simple chat loop.
Claude Code Mastery: From Autocomplete to Programmable Agent
Estimated read time: 22 min
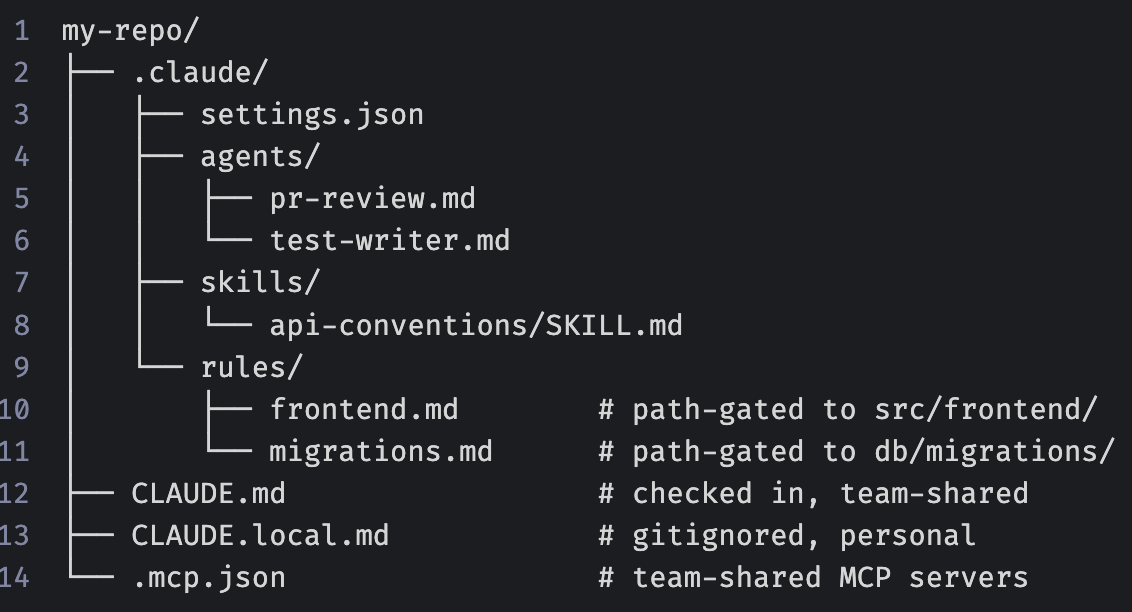
Going deeper, this guide reframes Claude Code as a programmable agent, drawing on Arpan Patel’s guidance. It covers the layered .claude directory, minimal CLAUDE.md files, compounding engineering through self-written rules, reusable skills, and custom subagents.
Key point: When Claude makes a mistake, ask it to update CLAUDE.md so the error never repeats; your config file becomes a curated list of every project gotcha.
Using LLMs to Secure Source Code: A Six-Step Loop
Estimated read time: 15 min
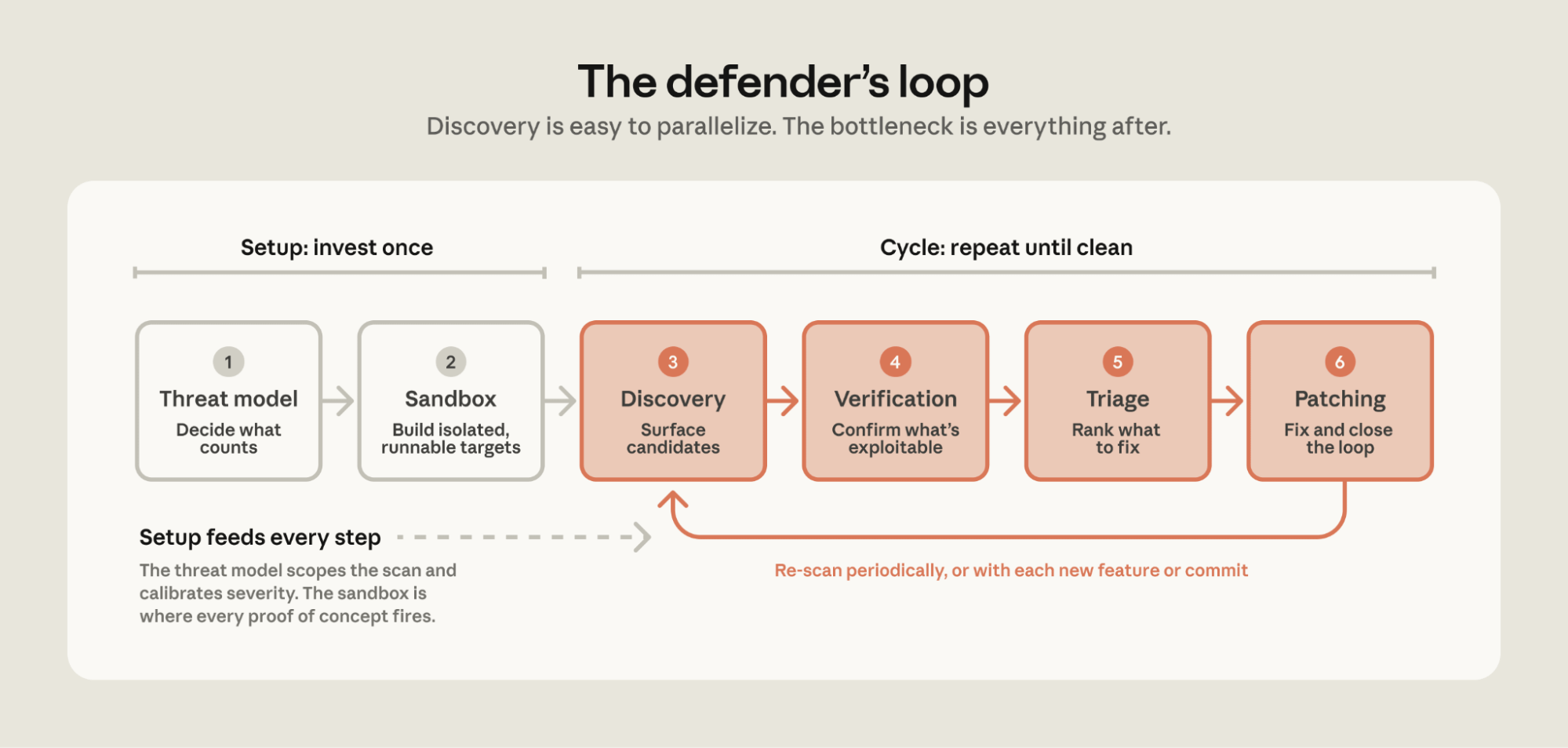
Putting agents to high-stakes work, Anthropic shares a playbook for using Claude Opus to find and fix vulnerabilities, noting that discovery is now easy to parallelize and the bottleneck has shifted to verification, triage, and patching, with guidance on threat modeling and sandboxing.
Worth noting: Invest upfront in a documented threat model and a production-faithful sandbox, because LLMs surface findings fast but context is what turns them into fixes.
When AI Agents Try to Do Qualitative Research
Estimated read time: 9 min
On the limits of agent autonomy, Shreya Shankar runs six agent setups on 451 tweets using grounded theory and finds agents paraphrase instead of analyzing, invent one-off codes for nearly every input, and silently stop partway through the corpus.
The context: For interpretive tasks, give agents explicit checkpoints and verify coverage yourself; they do best with a structured loop rather than freedom to self-pace.
How Far Behind Are Open Models?
Estimated read time: 9 min
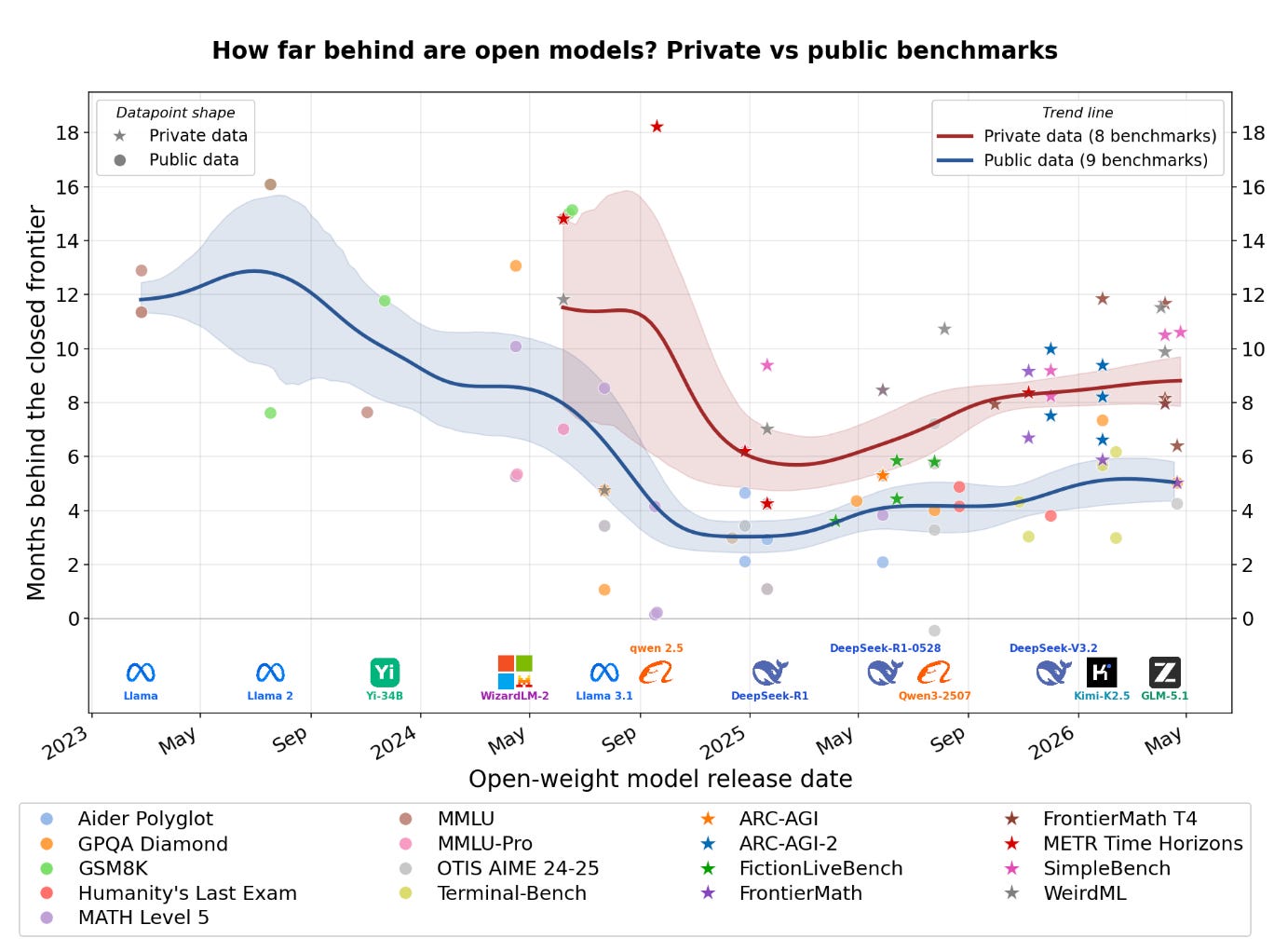
Building on our coverage of Cohere’s open-weight Command A+ release[1] from last week, this LessWrong analysis measures the gap between open-weight and frontier closed models in months rather than generations, offering a grounded look at benchmark trends and what the lag means for self-hosting decisions.
Why now: Before committing to a closed-model API, check the current open-weight gap; the lag is often shorter than you would assume, which widens your deployment options.
[1] Cohere Releases Command A+ as Open-Source MoE for Agentic Workloads
TOOLS
The tools cluster the way the models do: small, specialized, and tightly-coupled systems closing the gap with frontier agents, followed by the memory and practitioner playbooks that make those agents reliable.
Fara1.5: Microsoft’s Small Computer-Use Agents Punch Above Their Weight
Estimated read time: 9 min
 and WebVoyager (86.6 vs 73.5–80.2).")
Microsoft Research unveils Fara1.5, a family of browser computer-use agents at 4B, 9B, and 27B sizes. The 9B hits 63% on Online-Mind2Web, nearly doubling its predecessor, while the 27B competes with proprietary frontier agents.
What this enables: Small, open-weight agents are closing the gap with proprietary systems, making on-device browser automation a practical option rather than a cloud-only luxury.
Callstack’s Apex: A Specialized React Native Coding Model
Estimated read time: 5 min
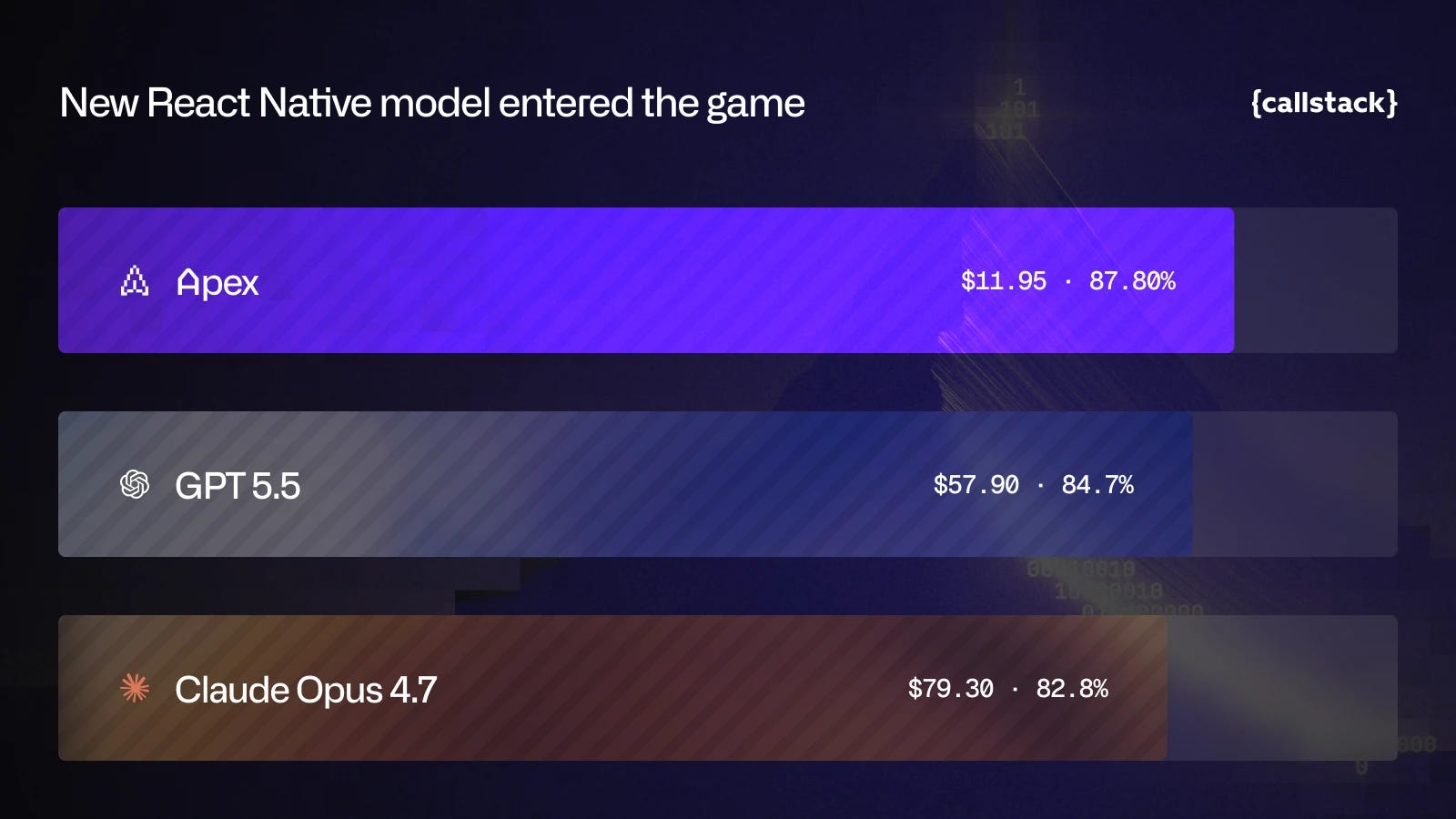
In the same vein, Callstack introduces Apex, a Gemma 4-based model fine-tuned for React Native. The release signals a shift toward specialized models that encode domain knowledge into weights, reducing tool calls. Apex hits 2,000-4,000+ tokens per second in private beta.
The opportunity: Domain-specific coding models can outperform general frontier models on narrow workflows while running faster and cheaper, a real edge for teams living in one stack.
Reasonix: A DeepSeek-Native Terminal Coding Agent
Estimated read time: 6 min
Taking that coupling further, Reasonix is an open-source terminal coding agent built exclusively around DeepSeek. Its append-only, byte-stable loop preserves DeepSeek’s prefix cache, holding ~94% cache hits and cutting input-token costs to roughly one-fifth on long sessions. MIT-licensed and MCP-native.
What’s interesting: Coupling tightly to one model’s cache mechanics can be a feature, not a limitation, when the economics scale with session length.
Supermemory: A Persistent Memory Layer for AI Agents
Estimated read time: 7 min
Shifting from models to infrastructure, Supermemory is a memory and context engine for AI that extracts facts, builds user profiles, resolves contradictions, and auto-forgets expired info. It combines RAG and memory in one API, ships an MCP server, and tops LongMemEval, LoCoMo, and ConvoMem.
Why this matters: If your agents keep forgetting who they are talking to, a dedicated memory layer is now a single API call away, with no vector DB plumbing required.
The Claude Code Field Manual: 83 Tips From Practitioners
Estimated read time: 15 min
To round out the toolkit, Shanraisshan’s repo maps the Claude Code ecosystem, from subagents and skills to hooks, MCP, and routers, and catalogs 83 practitioner tips organized around one pattern: Research, Plan, Execute, Review, Ship. A reference worth bookmarking.
Worth bookmarking: Treat context like a budget, keep sessions under 40% usage, rewind instead of correcting, and offload heavy work to subagents.
NEWS & EDITORIALS
The editorials trace the economics and the limits: agents found product-market fit and prices climbed, open models set a ceiling under that, adoption data shows where developers are pulling ahead, and a closing reminder that architecture still needs a human’s name on it.
The April Inflection: Coding Agents Find Product-Market Fit
Estimated read time: 9 min
Continuing our discussion of his six-month LLM recap[2] from last week, Simon Willison argues coding agents marked product-market fit for OpenAI and Anthropic in April 2026. Both labs moved enterprise plans to raw API pricing, frontier prices climbed, and runaway bills at Uber and Microsoft signal customers reluctantly saying yes.
The signal: The “shocking AI bill” stories are not failures, they are proof the business model finally works, so plan team agent budgets at API rates accordingly.
[2] Six Months of LLMs in Five Minutes: The November 2025 Inflection
When Outsourcing + Local AI Undercuts Frontier Labs
Estimated read time: 5 min
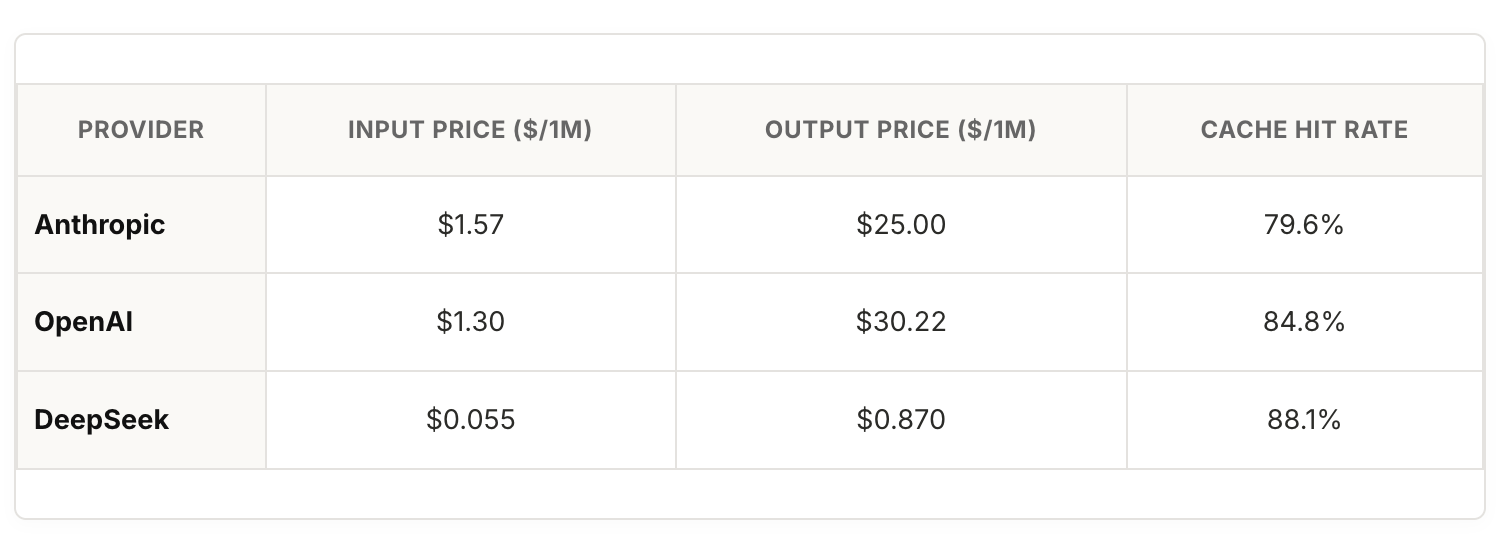
Pushing back on that pricing power, Max Trivedi runs the math and finds a 30x cost gap between frontier models and DeepSeek on blended agentic tokens, arguing a competent engineer plus a good-enough open model puts a hard ceiling on frontier pricing.
What this means: Frontier pricing has a ceiling, and the floor under it is a capable engineer with an open-source API key, which keeps your options open as costs rise.
Cursor’s Developer Habits Report: Five Signals of an Agentic Shift
Estimated read time: 9 min
Following our look at Cursor’s cloud-agent lessons[3] from last week, the company’s inaugural Developer Habits Report shows coding speed doubling year-over-year and agent-generated code surviving review at higher rates, alongside a widening power-user gap and surging context tokens.
The pattern: Treat context engineering and agent automation as core skills; input tokens now dominate cost, and the developers extracting the most value are pulling well ahead of the median.
[3] What Cursor Learned Building Cloud Agents
Claude Is Not Your Architect
Estimated read time: 8 min
Closing on the human side, Holland argues AI agents are pathologically agreeable, producing plausible architectures without context. The real risk isn’t bad designs but short-circuiting the messy engineering debate where good architecture emerges. When the Jenga tower wobbles at 3am, Claude isn’t on the pager.
The principle: Use AI to build faster, but keep a human’s name on every architectural decision worth defending; speed is cheap now, and judgment is what stays scarce.
That’s the week. The throughline: capability is settled, so the live questions are what it costs, who can undercut it, and which decisions still belong to a human. See you next Monday.