

Weekly Review: Show Your Work
The week's curated tutorials, tools, and news on AI development, grounded in data and field reports

Welcome to another edition of Altered Craft’s weekly AI review for developers. Thank you for making this part of your Monday. This week, the evidence is doing the talking. A 400-company study lands AI productivity gains at roughly 10%, a case study puts a 100-hour price tag on going from prototype to product, and a sensemaking framework argues you should ignore predictions entirely and follow field reports. Meanwhile, new coding models compete on benchmarks and pricing, and NVIDIA doubles down on agent security.
TUTORIALS & CASE STUDIES
MCP Is Dead, Long Live MCP: Why the CLI vs. MCP Debate Misses the Point
Estimated read time: 14 min
Continuing our coverage of the CLI-versus-MCP debate[1] from last week, Charles Chen argues the rush to abandon MCP for CLIs misses a crucial distinction. While CLIs save tokens for well-known tools, MCP over streamable HTTP unlocks centralized auth, telemetry, and security that enterprises need for structured agentic engineering at scale.
The takeaway: The real value isn’t in local stdio mode. It’s in the remote HTTP transport layer that enables org-wide auth, observability, and governance over agent workflows.
[1] Manus Lead Ditches Function Calling for Unix CLI
A Developer’s Guide to AI Agent Protocols: MCP, A2A, UCP, AP2, and A2UI
Estimated read time: 12 min

Expanding on the protocol question, Google’s developer blog demystifies five AI agent protocols by building a restaurant supply chain agent with ADK. Each protocol is layered incrementally, showing exactly what custom integration code MCP, A2A, UCP, AP2, and A2UI each replace.
What this enables: Instead of memorizing protocol specs, you see each one earn its place by eliminating real integration code in a practical, multi-step scenario.
The LLM Architecture Gallery: A Visual Reference from GPT-2 to Today’s MoE Models
Estimated read time: 4 min

For a visual reference to the models powering these protocols, Sebastian Raschka’s LLM Architecture Gallery collects standardized diagrams and fact sheets for major open-weight models from GPT-2 through DeepSeek V3, Llama 4, and Qwen3, documenting scale, attention type, and key design choices.
Worth bookmarking: When you need to quickly compare attention mechanisms, MoE configurations, or normalization strategies across modern LLM architectures, this is the single-page reference to reach for.
Context Anchoring: The Practice of Externalizing AI Session Memory
Estimated read time: 11 min
Shifting from architecture to workflow, Martin Fowler’s team introduces context anchoring: maintaining a living feature document outside the AI chat. The article shows how reasoning degrades faster than decisions in long contexts, and how a lightweight external record turns cold-start sessions into warm ones.
Why this matters: If closing your AI chat session causes anxiety about losing context, this lightweight practice turns any new session or new teammate into a warm start.
Lessons from Building Claude Code: A Taxonomy of Skills and How to Write Good Ones
Estimated read time: 12 min
In more practical developer workflow guidance, an Anthropic engineer catalogs nine skill categories and shares patterns for writing, distributing, and measuring Claude Code skills from hundreds in active internal use, including progressive disclosure via folder structure, iterative gotchas sections, and on-demand hooks.
Key point: The best skills at Anthropic grew from real failure points, not upfront design. Start small with a few lines and a gotchas section, then iterate as edge cases appear.
TOOLS
NVIDIA OpenShell: A Sandboxed Runtime for AI Agents That Actually Need Access
Estimated read time: 3 min
Following our coverage of NanoClaw’s Docker-based agent isolation[1] last week, NVIDIA open-sourced OpenShell, a runtime that sandboxes AI agents with kernel-level isolation and declarative YAML policies across filesystem, network, process, and inference layers, letting teams grant agents real capabilities without unrestricted access to credentials and source code.
The context: As coding agents gain access to production credentials and source code, policy-as-code enforcement is becoming table stakes. OpenShell gives enterprises an open-source baseline.
[1] NanoClaw Partners with Docker for Agent Isolation
NVIDIA NemoClaw: A One-Command “Secure Claw” Stack for AI Agents
Estimated read time: 2 min
Building on the OpenShell runtime, NVIDIA releases NemoClaw, an open-source stack adding policy-based privacy and security guardrails to OpenClaw autonomous agents. It routes to local Nemotron models for enhanced privacy and deploys everything with a single command.
Why now: Multiple teams are converging on the same pattern: sandboxed agent execution with local model routing for privacy. NemoClaw makes this a one-command setup.
Cursor Ships Composer 2: Frontier-Level Coding at Aggressive Pricing
Estimated read time: 2 min
Moving from agent infrastructure to coding models, Cursor releases Composer 2 with major gains on Terminal-Bench 2.0, SWE-bench Multilingual, and CursorBench through continued pretraining and RL on long-horizon tasks. Pricing at $0.50/M input tokens undercuts comparable fast models.
What’s interesting: The benchmark jumps over Composer 1.5 are substantial, and the aggressive pricing signals that frontier-level coding performance is becoming commoditized faster than expected.
OpenAI Launches GPT-5.4 Mini and Nano: Smaller Models Built for Speed-Sensitive Workloads
Estimated read time: 5 min
Also in the competitive coding model space, OpenAI releases GPT-5.4 mini and nano optimized for coding, subagents, and computer use. Mini hits 54.4% on SWE-Bench Pro at 2x the speed, offering a strong performance-per-latency tradeoff for agentic workflows. Nano targets classification at $0.20/M tokens.
What this unlocks: For multi-agent systems, mini at $0.75/M input tokens becomes the natural default for delegated subtasks where speed matters more than peak capability.
Mistral Launches Forge: Custom Frontier Model Training for Enterprises
Estimated read time: 7 min

For teams wanting models trained on their own data, Mistral AI introduces Forge, a platform for training frontier-grade models on proprietary enterprise data including codebases and compliance policies. Forge is agent-first, letting autonomous agents drive fine-tuning through natural language.
The opportunity: If your team has outgrown RAG-based approaches, Forge’s RL-based continuous improvement loop offers a practical path to custom enterprise models without building training infrastructure.
Claude Code Channels: Push Events from Telegram and Discord Into Your Coding Session
Estimated read time: 4 min
Shifting to developer experience tooling, Anthropic’s research preview introduces channels that push real-time Telegram and Discord events into running Claude Code sessions. Claude reads and replies through the same bridge, with sender allowlists for security. A localhost demo lets you test first.
Worth noting: This turns Claude Code from a pull-only tool into a reactive one, enabling workflows where your coding agent responds to external events while you’re away from the terminal.
APM: Microsoft’s Open-Source Package Manager for AI Agent Configuration
Estimated read time: 3 min
Also addressing AI developer tooling, Microsoft releases APM, bringing package.json-style dependency management to AI agent configuration. Teams declare prompts, skills, plugins, and MCP servers in one apm.yml manifest with transitive resolution and cross-agent support for Copilot, Claude Code, and Cursor.
Problem it solves: If your team manually configures AI coding agents per repo, APM lets you declare that setup once and reproduce it anywhere with a single install command.
NEWS & EDITORIALS
AI Productivity Gains Land at ~10%, Not the 2-3x Vendors Promised
Estimated read time: 3 min
Putting data behind our coverage of Rob Englander’s “AI did not simplify engineering” thesis[1] from last week, a DX longitudinal study across 400 companies finds that despite 65% growth in AI usage, PR throughput rose only ~10%. Developers explain that writing code was never the bottleneck. Planning, code review, and handoffs still dominate engineering time.
The data: Organizations should recalibrate expectations toward the 8-12% range and redirect investment toward the non-coding bottlenecks that AI hasn’t solved yet.
[1] AI Did Not Simplify Software Engineering
The 100-Hour Gap Between a Vibecoded Prototype and a Working Product
Estimated read time: 5 min
Illustrating that productivity gap in practice, this case study reveals a 100-hour gap between a vibecoded prototype and a production-ready product. The impressive AI-generated demo feels like most of the work, but edge cases, error handling, and deployment remain stubbornly manual.
The takeaway: Budget real engineering time beyond your prototype. The 100-hour figure gives teams a practical baseline for scoping the work AI doesn’t yet handle.
When LLM Exhaustion Is Actually a Skill Issue
Estimated read time: 4 min
On the developer experience side of that gap, Tom Johnell argues frustrating LLM sessions stem from developer fatigue, not model degradation. He identifies a “doom-loop psychosis” where tired prompting and slow feedback loops waste hours. The fix: treat prompt confidence as an energy signal.
The fix in practice: If you’re not confident your prompt will nail the result before you hit submit, you likely need a break or haven’t decomposed the problem enough.
A Sensemaking Framework for AI: Ignore Predictions, Follow Field Reports
Estimated read time: 15 min
For a broader lens on navigating these challenges, Cedric Chin studies past tech revolutions and argues for ignoring all AI predictions. Instead, collect detailed field reports of actual use and filter them through four questions about outcomes, actions, value, and causation.
How to apply it: The four-question filter (outcomes, actions, value, causation) gives you a repeatable framework for evaluating any AI capability claim against your own context.
Cerebras Brings Wafer-Scale Inference to AWS, Introduces Disaggregated Architecture with Trainium
Estimated read time: 4 min
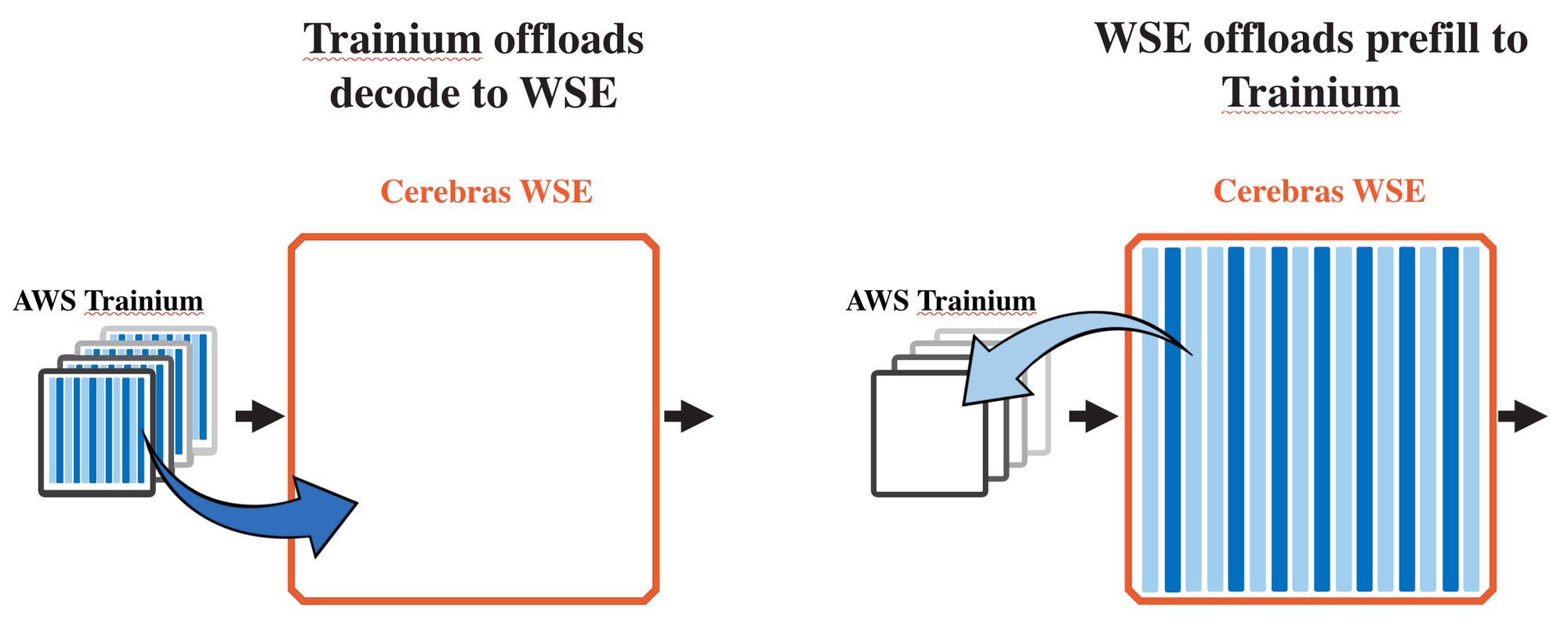
Shifting to industry moves, Cerebras announces AWS will deploy CS-3 systems via Bedrock. Their disaggregated inference architecture splits prefill across Trainium and decode across Cerebras WSE, targeting 5x more high-speed token capacity for agentic coding workloads.
Market signal: Agentic coding generates roughly 15x more tokens than chat. This partnership directly targets the inference bottleneck that makes token-heavy agent pipelines expensive to scale on AWS.
OpenAI Acquires Astral, Bringing Python’s Most Popular Dev Tools Into Codex
Estimated read time: 3 min
In more industry consolidation news, OpenAI announces its acquisition of Astral, creators of uv, Ruff, and ty, folding Python’s widely adopted open source tools into Codex. OpenAI commits to continued open source support while integrating for full-lifecycle AI agent development.
Worth watching: If your Python workflow depends on uv, Ruff, or ty, the roadmap for those tools now runs through OpenAI’s Codex strategy. Watch for governance and licensing signals post-close.
MiniMax M2.7: The Model That Helps Build Its Own Next Version
Estimated read time: 10 min
On the model development front, MiniMax releases M2.7, a model that actively participates in its own evolution by autonomously optimizing scaffolds and running RL experiments. It scores 56.22% on SWE-Pro and now manages 30-50% of MiniMax’s internal RL workflow.
What stands out: The self-evolution loop, where the model iterates its own scaffolding and training, signals a shift from models as passive outputs to active participants in their own development.
The 3 Cs Framework: How Open Source Maintainers Can Mentor Strategically in the AI Era
Estimated read time: 8 min
Returning to the human side of AI’s impact, AI-generated pull requests are flooding open source projects, eroding traditional quality signals. GitHub’s Abigail Cabunoc Mayes proposes the 3 Cs framework -- Comprehension, Context, and Continuity to help maintainers invest mentorship energy strategically.
The opportunity: Whether you maintain or contribute to open source, the 3 Cs give you a practical filter for where to invest mentorship energy when traditional quality signals are unreliable.