

Weekly Review: Pulled Offline
A government pulls two frontier models offline overnight, and why owning your stack, from a neuron by hand to a model for $80, is more interesting then ever

Welcome back to Altered Craft’s weekly AI review for developers, and thank you for being here for a heavy news week. The defining story is sobering: a US government directive forced Anthropic to pull Fable 5 and Mythos 5 offline for every customer, the first time a nation has recalled a deployed frontier model. A model you build on can now vanish overnight. So the rest of this issue leans into the hedge: build from first principles, route to smaller models, own more of your stack.
TUTORIALS & CASE STUDIES
We start at the foundations and climb: one neuron by hand, a full from-scratch curriculum, a tiny model trained for $80, then serving it efficiently and prompting the latest frontier release.
The Perceptron, Built From Scratch in Your Browser
Estimated read time: 8 min
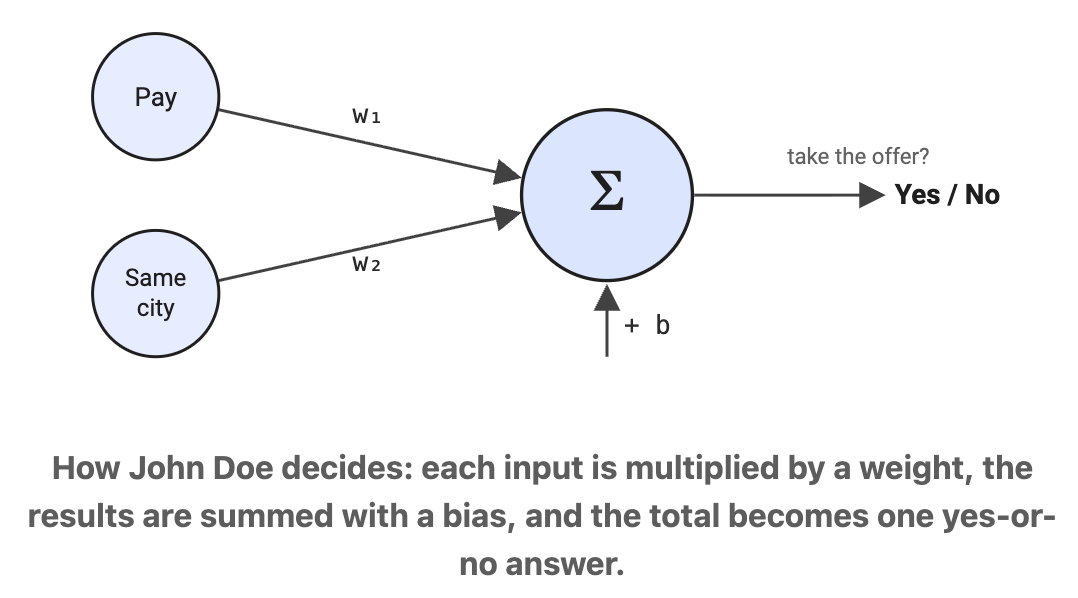
Ranpara builds a single perceptron in plain Python and runs it live so you watch it learn. A student-pass example shows why the bias moves the boundary to where the answer lives, plus how normalization keeps training smooth.
The takeaway: Understand the weight, bias, and update loop of a single neuron and you understand the building block every neural network is made from.
503 Lessons That Build AI From Raw Math Up
Estimated read time: 9 min
From a single neuron to the full stack, this free, open-source curriculum spans 20 phases and 503 lessons across four languages. Its core principle: build every algorithm from raw math before touching a framework. Every lesson ships a reusable artifact, a prompt, skill, agent, or MCP server.
Why this matters: If you can call AI APIs but can’t explain what happens underneath, this curriculum closes that gap by making you build each piece by hand.
Building a Victorian LLM From (Almost) Scratch for $80
Estimated read time: 31 min
Putting that build-it-yourself ethos to the test, Cristi Constantin trains a 340M-parameter, Llama-based model knowledge-locked to the year 1900. The standout lesson: data quality, not compute, dominates the work, through custom de-duplication, compression ratios, entropy, and OCR scoring. Total GPU cost: roughly $80.
Key point: To truly understand how LLMs work, build a small one yourself, and expect most of your time to go into cleaning and filtering the data.
Serving LLMs Efficiently: A Hands-On vLLM Workflow
Watch time: 1h38m

Once a model exists, the next problem is serving it. This DeepLearning.AI course, built with Red Hat, shows that efficient LLM serving is mostly a memory problem, where weights and the KV cache compete for GPU space. You quantize a Qwen model, serve it with vLLM, and benchmark under load.
What this enables: Treat LLM deployment as a memory-management problem, then use quantization with vLLM’s PagedAttention and continuous batching to balance speed, cost, and accuracy.
Prompting Patterns for Claude Fable 5: What Changes When the Model Runs for Hours
Estimated read time: 7 min
At the frontier end of the spectrum, and newly poignant this week, Anthropic’s guide details the prompting shifts for Claude Fable 5 and Mythos 5, the very models just pulled offline. Because instruction-following is now strong enough to steer briefly, older prescriptive prompts can degrade output and need pruning before migration.
Try this: Re-audit your prompts and skills before migrating, since instructions tuned for older models can actively hurt Fable 5’s output. Call it homework for whenever it comes back. If it comes back.
TOOLS
This week’s tools equip the agent itself: the new frontier model to drive it, a brain and a sandbox to work in, an interface built for it, and a guardrail to keep it safe.
Serena: Giving Your Coding Agent an IDE’s Brain
Estimated read time: 8 min
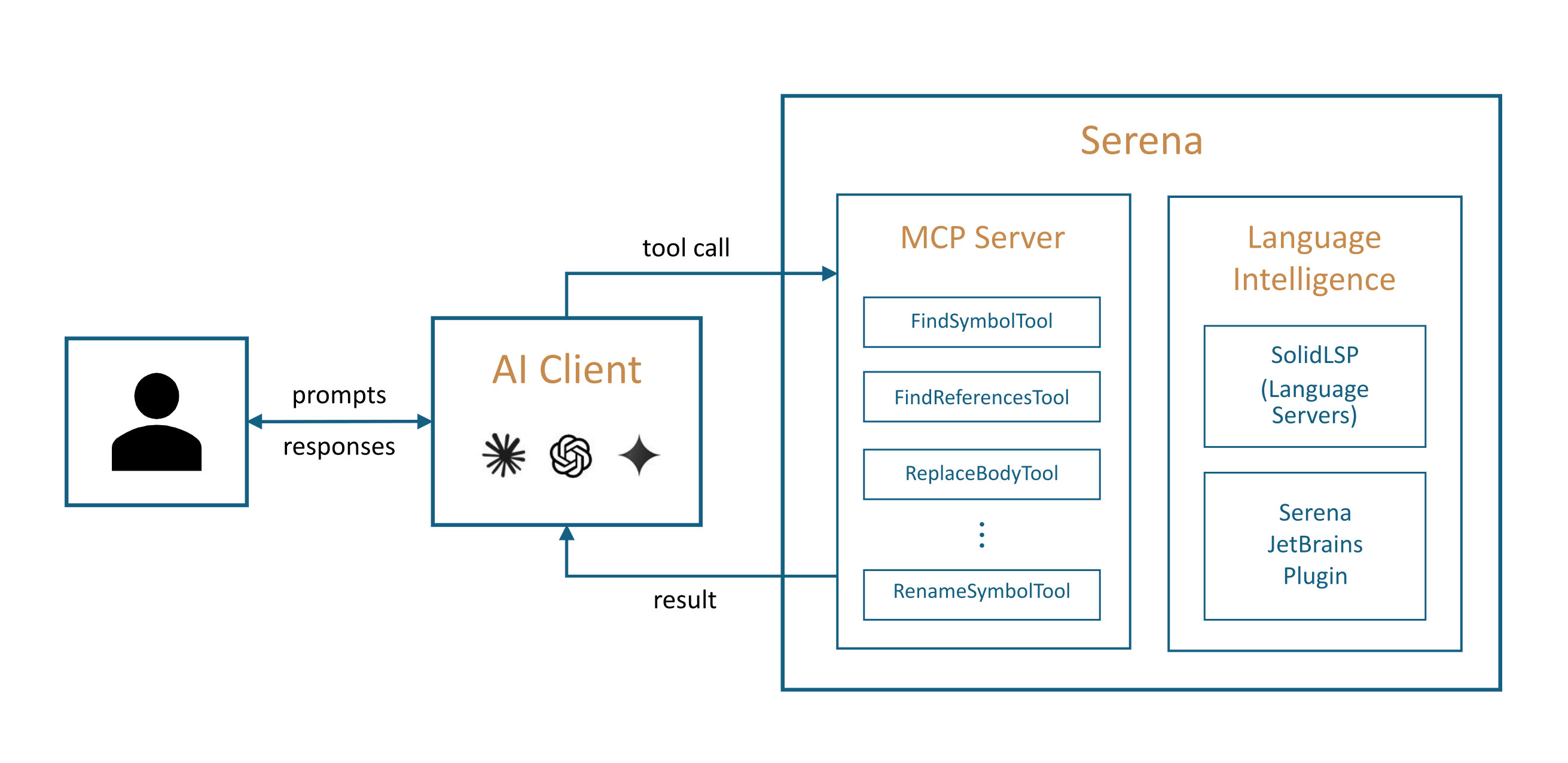
To make any model useful in a large codebase, Serena is an open-source MCP server that gives coding agents semantic, symbol-level understanding of code instead of brittle text search. Backed by language servers across 40+ languages, it turns cross-file renames, lookups, and refactors into single atomic calls.
The opportunity: If your agent fumbles refactors with search-and-replace in a large codebase, an MCP server like Serena can collapse eight to twelve error-prone steps into one reliable operation.
Every Agent Needs Its Own Computer
Estimated read time: 6 min
If a brain handles the code, the next need is a safe place to run it. LangChain introduces LangSmith Sandboxes, hardware-virtualized microVMs that give each agent a disposable computer with filesystem, shell, and persistent state. The piece argues containers aren’t an isolation boundary for untrusted model-generated code.
The principle: If your agent runs dynamic or model-generated code, give it a hardware-isolated sandbox rather than a shared-kernel container you are quietly trusting.
Designing the hf CLI for Humans and Agents Alike
Estimated read time: 9 min
Tools also have to speak the agent’s language. Hugging Face rebuilt its hf CLI to serve both humans and coding agents, auto-detecting which is driving and rendering output accordingly. Benchmarks show a no-CLI baseline burns up to 6x the tokens on complex multi-step tasks.
Worth noting: Designing tool output for agents, compact, parseable, and full of next-command hints, can cut token usage dramatically without hurting the human experience.
Nemotron 3.5 Brings Custom Policy Reasoning to Multimodal Safety
Estimated read time: 9 min
Finally, a guardrail for everything above. NVIDIA’s 4B-parameter safety model unifies multimodal input, 12-language coverage, and custom enterprise policy enforcement in one inference call. The standout is auditable reasoning traces via THINK mode, letting teams enforce natural-language policies with a documented justification per verdict.
What this enables: If you build guardrails for regulated or multi-domain AI products, one model that accepts custom policies and emits auditable traces could replace a stack of brittle classifiers.
NEWS & EDITORIALS
The editorials open on the week’s biggest shock, a frontier pulled offline by government order, then widen out: the architecture you actually control, clearer thinking about “world models,” the economics pushing toward cheaper ones, and the part of the job that stays yours.
The Government Just Pulled Two Anthropic Models Off the Market
Estimated read time: 4 min
In an action without precedent, a June 12 US export-control directive ordered Anthropic to suspend Fable 5 and Mythos 5 for any foreign national, and the company disabled both models for everyone worldwide. Anthropic disputes the cited jailbreak, reading a codebase to fix its flaws, as narrow and reproducible in rival models, and says it is working to restore access.
Worth watching: Frontier access is something regulation can revoke overnight. Keep a fallback model and own more of your stack.
The AI Agents Stack: 2026 Edition
Estimated read time: 9 min
If a model can vanish overnight, the architecture you control matters more. Paolo Perrone redraws Letta’s influential agent stack diagram for 2026, mapping six layers from models to guardrails. The recurring argument: add complexity only when something specific breaks, with honest takes on lock-in and the demo-to-production gap at each layer.
The pattern: Start with the simplest stack that works and add layers only when something specific breaks, not in anticipation of problems you don’t yet have.
A Functional Taxonomy of World Models
Estimated read time: 9 min
Another effort to bring order to a loaded term, Fei-Fei Li and World Labs sort “world model” systems into three functions: renderers output pixels, simulators output state, planners output actions. They argue simulation is the structural backbone from which fidelity and reliable action derive.
The lens: When evaluating a “world model,” ask which contract it fulfills, visual plausibility, structural accuracy, or correct action, because beautiful pixels rarely guarantee usable physics.
The Coming Shift From Bigger Models to Cheaper Ones
Estimated read time: 5 min
Building on our coverage of open versus closed model economics[1] last week, the question sharpens as subsidies slow and token prices climb: are companies ready to switch to smaller models? Early tests, like Harvey cutting inference costs 3x with no quality loss, suggest the real divide is large versus small.
Why now: Stop defaulting to the frontier model for everything and start routing each task to the smallest model that returns the right answer.
[1] Open and Closed Models Are on Different Exponentials
The “Decide-Execute-Deliver” Sandwich: Why AI Hasn’t Replaced Engineers
Estimated read time: 9 min
We close on what stays yours. Following our look at how the senior role is moving from writing code to directing it[2] last week, this essay examines headline layoffs at Block, Snap, and Intuit and finds AI is mostly a scapegoat for financial restructuring. Software work is a decide-execute-deliver sandwich: AI compresses the middle, but deciding what to build and owning delivery resist automation.
The shift: Code generation was never the bottleneck. Your value increasingly lives in framing problems and owning what ships, not in typing the implementation.
[2] When AI Starts Building AI: Inside Anthropic’s Self-Improvement Curve