

Weekly Review: Past the Threshold
The work that becomes load-bearing once coding agents are reliably useful: sensors, harnesses, evaluations, runtimes, and editorials testing the headlines

Welcome to Altered Craft’s weekly AI review for developers. Grateful you keep showing up. Simon Willison’s six-month recap names November 2025 as when coding agents crossed from often-work to mostly-work, and that shift is the spine of this edition. Tutorials cover what becomes load-bearing past the threshold: sensors, harness scaffolding, output formats, and rigorous evals. The tools track production-grade arrivals, and the editorials test popular claims with data, logic, and hard-won lessons from a year of cloud agents.
TUTORIALS & CASE STUDIES
What becomes load-bearing once the model is mostly-work: a six-month recap to set the temporal anchor, harness scaffolding, feedback sensors, output formats developers actually engage with, and rigorous evaluations.
Six Months of LLMs in Five Minutes: The November 2025 Inflection
Estimated read time: 5 min

Simon Willison’s annotated PyCon US 2026 lightning talk recaps six months of LLM progress, marking November 2025 as when coding agents crossed from often-work to mostly-work. He tracks the frontier crown changing hands five times and surprisingly capable open-weight releases.
The takeaway: Coding agents have crossed a usability threshold where they can serve as daily drivers, and open-weight models running on local hardware are catching up faster than many expected.
Harness Engineering: Building Reliable AI Coding Agents
Estimated read time: 3 min
Extending our coverage of Anthropic’s harness patterns for large codebases[1] from last week, this course teaches reliable AI coding agent engineering drawing on OpenAI and Anthropic research. Its core insight: a harness doesn’t make the model smarter, it builds a closed-loop system around it through explicit rules, state management, and verification.
Why this matters: Reliable agentic coding is less about better prompts and more about building the scaffolding that keeps capable models from declaring victory too early in a long-running session.
[1] Scaling Claude Code: Patterns for Large Codebases
Sensors for Coding Agents: Rethinking Static Analysis in the AI Era
Estimated read time: 9 min
Zooming into one piece of that closed loop, Birgitta Böckeler experiments with feedback sensors that help AI agents self-correct on maintainability, from ESLint to mutation testing. Custom lint messages guide agents toward better refactorings, and AI shifts the cost-benefit of static analysis.
Practical tip: Treat linters as feedback channels for your coding agent, and write custom guidance messages that teach it when to refactor versus when to suppress a warning with written justification.
Why HTML Beats Markdown for Claude Code Output
Estimated read time: 8 min

Shifting from agent-facing feedback to developer-facing output, Thariq Shihipar argues that HTML outperforms Markdown for Claude Code output across specs, reviews, and prototypes. Its density, visual clarity, and support for interactive elements like sliders and export buttons help developers stay engaged with Claude’s choices.
Worth noting: Stop asking Claude Code for Markdown plans you won’t read, and start requesting HTML artifacts you’ll actually engage with, share with teammates, and review carefully.
A Practical Framework for Evaluating AI Agents
Estimated read time: 22 min
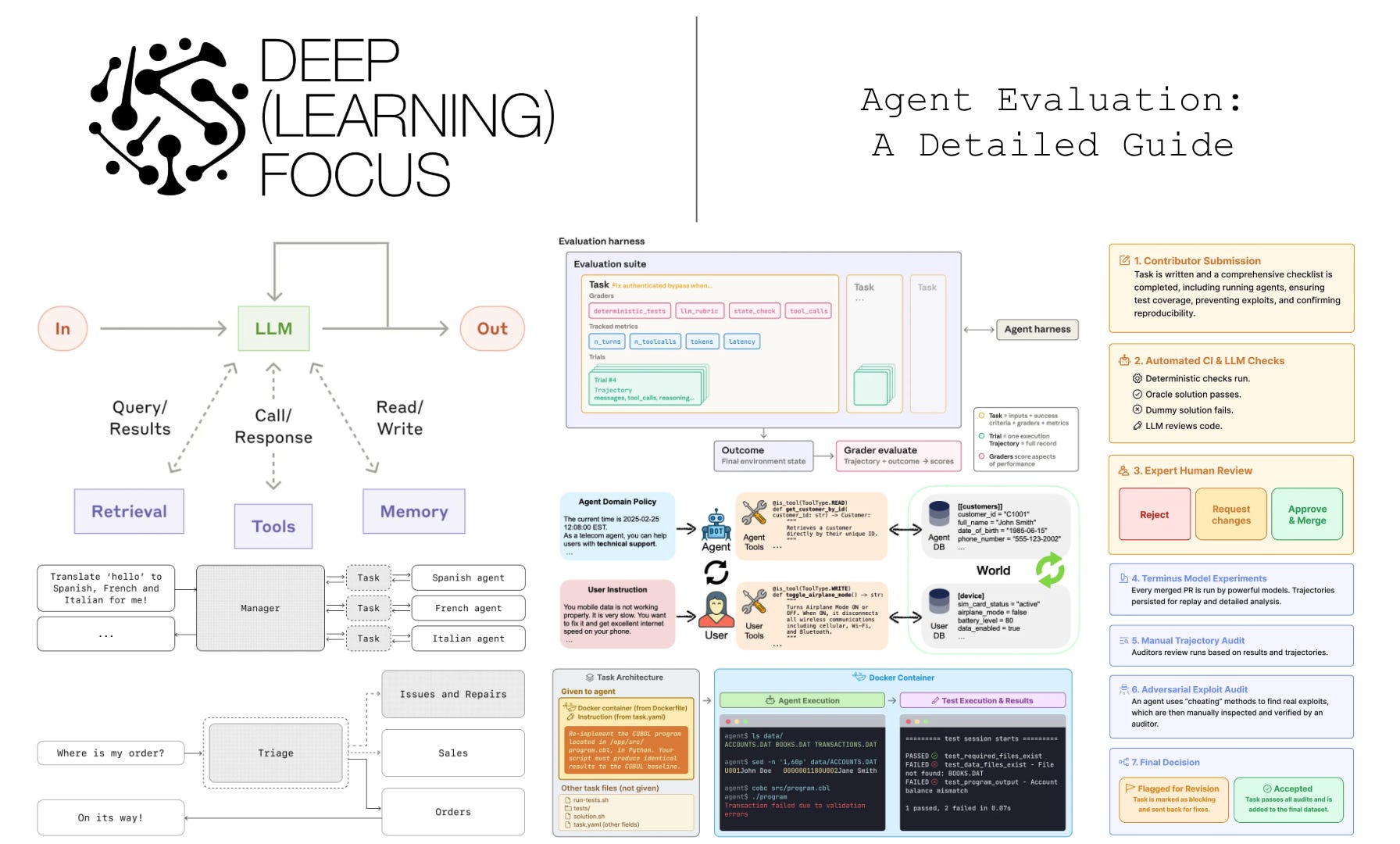
Closing the section on measuring rigorously, Cameron Wolfe delivers a thorough guide on how to rigorously evaluate agent systems, moving beyond static LLM benchmarks. The piece covers tool calling metrics, reasoning models, ReAct loops, and multi-agent architectures, with case studies and a roadmap.
Key point: Start with a single-agent design and rigorous evaluation harnesses before reaching for multi-agent complexity, because anecdotal checks cannot tell you whether your agent actually works.
TOOLS
This week’s tools span both ends of the model spectrum and both ends of the agent lifecycle: a faster frontier release, an open-weight MoE catching up, a durable runtime for long-running agents, and a real production case study.
Gemini 3.5 Flash Targets Long-Horizon Agentic Workflows
Estimated read time: 5 min

Google’s Gemini 3.5 Flash beats Gemini 3.1 Pro on coding and agentic benchmarks while running 4x faster. It hits 76.2% on Terminal-Bench 2.1, powers subagent workflows via Antigravity, and ships today across the Gemini app, AI Studio, and Enterprise.
What this enables: Frontier-level agentic coding no longer demands flagship latency or cost, making multi-step subagent workflows viable for everyday developer use rather than reserved for special runs.
Cohere Releases Command A+ as Open-Source MoE for Agentic Workloads
Estimated read time: 9 min
On the open-weight side, Cohere released Command A+ under Apache 2.0, a 218B mixture-of-experts model with 25B active parameters that runs on two H100s or one Blackwell GPU. It unifies reasoning, multimodal, and tool-use across 48 languages, with notable gains on agentic coding benchmarks.
Why now: If you’re building privately deployable agents, an Apache 2.0 MoE model that fits on two H100s with near-lossless 4-bit quantization is worth a serious look this quarter.
Google’s Agent Executor: A Runtime for Long-Running Agents
Estimated read time: 5 min

Moving from models to the runtime that holds them, Google open-sources Agent Executor, a runtime tackling the fragility of long-running agents with durable execution, secure sandboxing, and session consistency. It pairs with Agent Substrate for Kubernetes scaling and supports LangGraph, ADK, and A2A agents without vendor lock-in.
Where to invest: If you’re deploying agents that run for hours, treat the runtime layer as seriously as the model, because durability and state consistency are now infrastructure concerns.
How Uber Automated Design System Specs with AI Agents and Figma MCP
Estimated read time: 9 min

Closing on production deployment, Uber’s design team built uSpec, pairing Cursor with the open-source Figma Console MCP to generate component specs in minutes. The pipeline runs entirely locally so proprietary data never leaves the network, blending AI judgment with programmatic rendering into Figma.
The opportunity: Pairing AI agents with local MCP bridges can collapse weeks of documentation work into minutes without compromising enterprise data security or external review.
NEWS & EDITORIALS
The editorial throughline runs the same way: reality-checking the headlines. Two pieces test popular claims, one pushes back on a category framing, one reports hard-won production lessons, and one watches where talent actually moves.
Is “Model Half-Life” Actually a Real Thing?
Estimated read time: 3 min
Paul Kinlan tests the claim that AI model release cadence keeps halving by compiling frontier drops from US and Chinese labs since 2022. His verdict: activity has upticked, but “halving” is more buzzword than data.
Worth noting: Models are shipping faster, but resist extrapolating exponential curves from a handful of data points.
AI Won’t Speed Up Your Process (The Bottleneck Is Upstream)
Estimated read time: 5 min
Resonating with our coverage of Unmesh Joshi’s code-as-vocabulary argument[2] from last week, Frederick Van Brabant argues AI code generation won’t deliver expected speedups because long duration doesn’t mean the problem originates there. Software is slow due to vague requirements, and AI just shifts that handholding burden upstream.
The principle: If your team can’t write a clear spec for a human reviewer, handing it to AI won’t save you time, it will just move the bottleneck somewhere harder to see.
[2] What Is Code? Rethinking Value in the Age of LLMs
AI Is Technology, Not a Product
Estimated read time: 6 min
Shifting from process to category, John Gruber pushes back on calls for Apple to ship a “killer AI product,” arguing AI will pervade everything like wireless networking rather than manifest as a hero device. Actual experiences still require actual products with microphones, speakers, and screens.
The context: Stop chasing a “killer AI product” and treat AI as ambient infrastructure that makes existing products better in ways customers may not even name.
What Cursor Learned Building Cloud Agents
Estimated read time: 8 min

From category back to production reality, Cursor reflects on a year of cloud agents, finding the work looks less like porting local agents and more like building an operating layer around them. Lessons span environment reconstruction, durable execution via Temporal, and shifting trust from harness to agent.
Heads up: If you’re running agents in the cloud, treat the development environment itself as the product, because output quality degrades silently when it’s incomplete or out of date.
Karpathy Joins Anthropic
Estimated read time: 1 min
Closing on a talent signal, Andrej Karpathy announces he is joining Anthropic to return to frontier LLM R&D, calling the next few years especially formative. The former OpenAI co-founder also plans to resume his education work in time.
Why now: Watch where top researchers land, because talent migration is one of the clearest signals of where the frontier AI work is actually happening this cycle.
That’s the week. The throughline: when capability becomes table stakes, the work moves into the scaffolding around it, and into honest testing of every claim that surrounds it. See you next Monday.