

Weekly Review: Know Your Harness
This week's curated tutorials, tools, and news on the infrastructure that makes AI models actually useful

Welcome back to Altered Craft’s weekly AI review for developers. Thanks for making this part of your Monday routine. This week’s recurring message: the infrastructure around models matters more than the models themselves. Sebastian Raschka maps the six components of a coding agent, Martin Fowler makes the case for versioning team AI instructions, and Cursor redesigns the IDE around parallel agents. Gemma 4 and Ollama 0.19 also arrive to make local-first AI genuinely practical.
TUTORIALS & CASE STUDIES
Encoding Team Standards as Executable AI Instructions
Estimated read time: 12 min
Rahul Garg argues that tacit team knowledge should become versioned, executable AI instructions stored in the repo. By extracting senior engineers’ instincts into structured instruction sets, teams close the consistency gap and make inexperience less costly.
Key point: Treating AI instructions like linting rules or CI config turns tribal knowledge into a versioned team asset. The consistency gains compound as teams scale.
Anatomy of a Coding Agent: Six Core Components That Make LLMs Actually Useful
Estimated read time: 14 min
Complementing our look at Anthropic’s generation/evaluation split for long-running coding tasks[1] last week, Sebastian Raschka argues the harness around a coding agent matters as much as the model. He maps six building blocks, from repo context and prompt caching to tool validation and context compaction, with a companion open-source Mini Coding Agent in pure Python.
The takeaway: When evaluating coding agents, focus less on which base model they use and more on how their harness handles context management, tool validation, and session continuity.
[1] Anthropic’s GAN-Inspired Multi-Agent Harness for Long-Running Autonomous Coding
How Dropbox Used DSPy to Cut Relevance Judge Costs While Improving Human Alignment by 45%
Estimated read time: 12 min
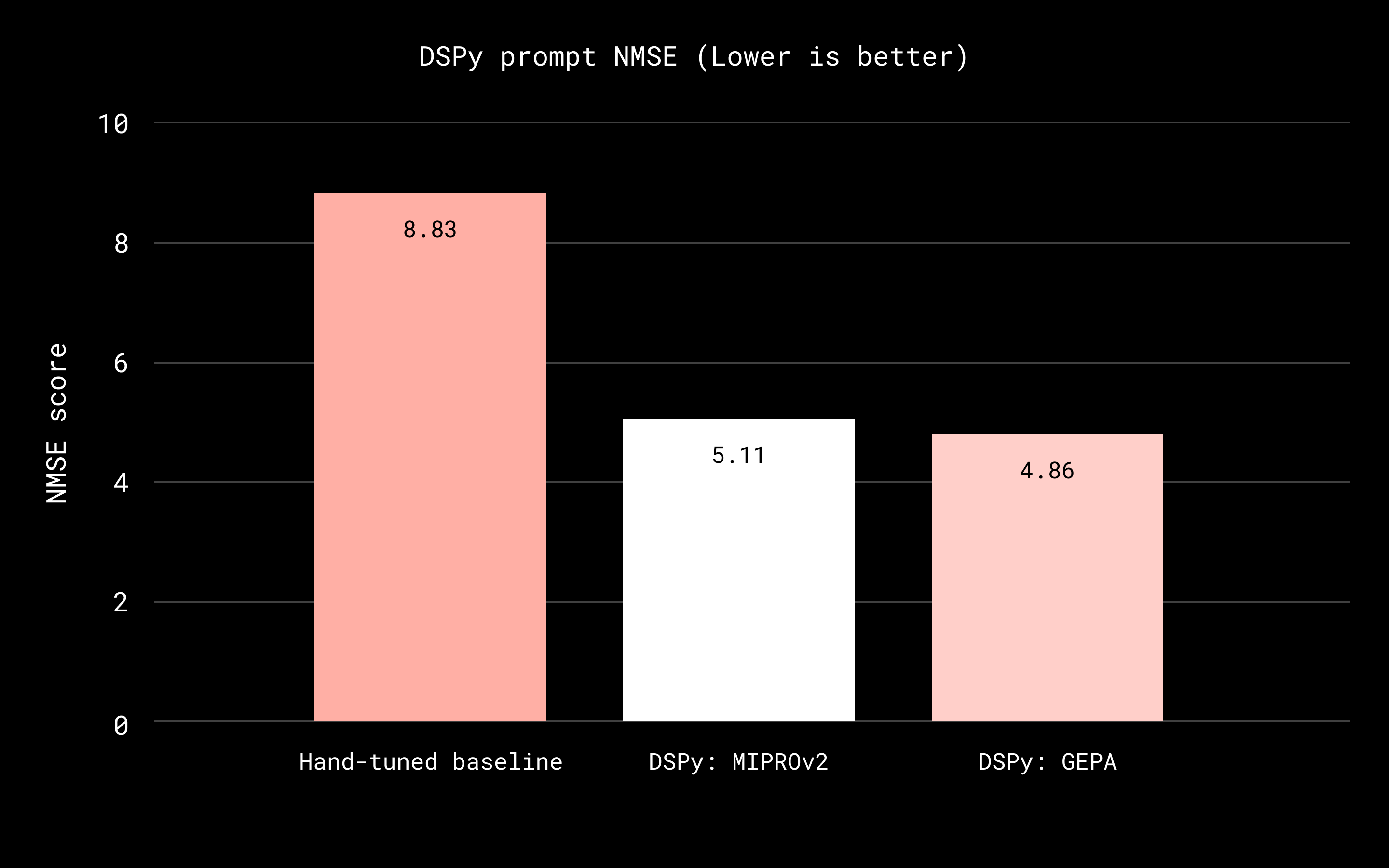
Supporting our coverage of Skylar Payne’s argument that teams inevitably reinvent DSPy patterns[1] last week, Dropbox details how DSPy systematically optimized LLM-as-a-judge prompts for Dash search, reducing human-alignment error by 45% while migrating to cheaper models. The team cut malformed outputs by 97% and introduced an instruction library for safe, incremental production improvements.
Why this matters: Systematic prompt optimization compresses weeks of manual tuning into days. If you’re scaling LLM judges across models, DSPy’s task/data/metric loop is a proven pattern.
[1] You’re Already Building DSPy, Just Worse
Free 1.5-Hour Course Covers GitHub Copilot, Claude Code, Gemini CLI, and More
Watch time: 1.5 hour
freeCodeCamp releases a free 1.5-hour video course on AI pair programming and agentic terminal workflows featuring GitHub Copilot, Claude Code, Gemini CLI, and OpenClaw. The walkthrough also covers CodeRabbit for automated pull request analysis.
Worth noting: A single, free walkthrough comparing the leading AI dev tools side by side. If you’ve been wanting to evaluate your options, 90 minutes well spent.
TOOLS
OpenYak: An Open-Source Desktop AI Agent That Keeps Your Data Local
Estimated read time: 3 min
OpenYak is an open-source desktop AI assistant that keeps files, conversations, and memory on your machine. It supports 100+ cloud models or fully local inference via Ollama, with 20+ built-in tools, cron-based automation, and MCP connector support.
What this enables: A fully offline AI agent that manages files, analyzes data, and automates workflows. Ollama integration means you can run the entire stack without cloud dependencies.
lat.md: A Knowledge Graph for Your Codebase, Written in Markdown
Estimated read time: 4 min

AGENTS.md doesn’t scale. lat.md offers a knowledge graph of interconnected markdown files linked via wiki syntax and validated by CLI. Agents navigate the graph instead of grepping, capture session context for future runs, and enforce test coverage through backlink checks.
What’s interesting: If your AGENTS.md is becoming a monolith, this is a structured, agent-navigable alternative that keeps design decisions and test specs linked to the code that implements them.
Google Releases Gemma 4: Apache 2.0 Licensed Models Built for Agentic Workflows
Estimated read time: 6 min
Following our coverage of MiniMax M2.7 matching frontier detection quality at 7% of the cost[1] last week, Google DeepMind launches Gemma 4 in four sizes under Apache 2.0 licensing. The 31B model ranks #3 among open models, outperforming models 20x its size. All variants include native function-calling, structured JSON output, and up to 256K context windows.
Why now: Permissively licensed open models with native agentic capabilities that run on consumer hardware have been the missing piece. Gemma 4 removes the last major licensing barrier.
[1] MiniMax M2.7 vs. Claude Opus 4.6: 90% of the Quality at 7% of the Cost
Ollama 0.19 Ships MLX Backend for Apple Silicon, Nearly Doubling Performance
Estimated read time: 4 min

Ollama 0.19 previews a backend built on Apple’s MLX framework, hitting 1,810 tokens/s prefill and 112 tokens/s decode on M5 chips. It adds NVFP4 quantization for production parity and smarter KV cache reuse that accelerates coding agents like Claude Code.
The context: If you’re running coding agents locally on a Mac with 32GB+ unified memory, this is now the fastest path to usable token throughput on Apple Silicon.
Cursor 3: A Unified Workspace for Multi-Agent Software Development
Estimated read time: 4 min
Cursor ships a ground-up redesign with a unified workspace built around parallel agents rather than file editing. The new interface supports multi-repo layouts, local-to-cloud agent handoff, an integrated browser, a plugin marketplace, and a streamlined diffs-to-PR workflow.
The signal: IDEs are evolving from file editors to agent orchestration platforms. Cursor’s redesign around parallel agents rather than file tabs shows where developer tooling is heading.
Google Ships MCP Server and Skills to Keep Coding Agents Current on Gemini APIs
Estimated read time: 1 min

Google releases two tools to fix stale coding agent output for Gemini APIs. The Docs MCP server and Developer Skills connect agents to live documentation and best-practice patterns, achieving a 96.3% eval pass rate with 63% fewer tokens.
The pattern: Stale training data is the top source of hallucinated API calls. Connecting coding agents to live documentation is an approach every API provider will likely adopt.
LLMOps in 2026: A Tool for Every Layer of the Production Stack
Estimated read time: 6 min
This roundup maps ten tools to distinct LLMOps production layers, from orchestration and routing to memory, guardrails, and packaging. Rather than listing popular names, it identifies one strong tool per production concern covering PydanticAI, Bifrost, Promptfoo, Letta, and KitOps among others.
The shift: The competitive question in LLMOps has moved from which model to use to how well you connect, evaluate, and harden everything around it.
NEWS & EDITORIALS
Google’s TurboQuant: 6x KV Cache Compression That Could Reshape AI Memory Economics
Estimated read time: 14 min
Google’s TurboQuant achieves 6x KV cache compression with no accuracy loss by converting vectors to polar coordinates and correcting residual error via Johnson-Lindenstrauss transforms. The data-oblivious approach needs no per-model calibration, with implications for vector databases and on-device inference.
The opportunity: If your inference costs or context-length limits are bottlenecked by KV cache memory, TurboQuant’s open-source PolarQuant and QJL components are available now and worth evaluating.
A Mirror Test for LLMs: Can Language Models Recognize Themselves?
Estimated read time: 8 min
A LessWrong post proposes adapting the classic animal cognition mirror test for LLMs, asking whether models can recognize their own outputs versus those of other models. The piece explores what self-recognition reveals about machine cognition and model identity.
The bigger picture: As LLMs grow more capable, the frameworks we use to probe their cognition matter as much as the benchmarks we use to measure their performance.
Claude Code’s Source Leaks: Anti-Distillation, Client DRM, and an Unreleased Agent Mode Called KAIROS
Estimated read time: 11 min
An accidental source map leak in Claude Code’s npm package exposed Anthropic’s full codebase, revealing anti-distillation defenses, client attestation DRM, and an unreleased autonomous agent mode called KAIROS with background daemons and cron jobs. Feature flags hint at Anthropic’s broader product roadmap.
Worth noting: The leaked feature flags and product roadmap, not the code itself, represent the real strategic damage. Accidental exposures carry consequences well beyond intellectual property.
Anthropic Cuts Off Claude Code Subscribers From OpenClaw Usage
Estimated read time: 3 min
Anthropic now requires Claude Code subscribers to pay extra for third-party harness usage starting with OpenClaw. The change lands days after OpenClaw’s creator joined OpenAI, raising questions about competitive motives versus sustainability concerns.
Heads up: If your workflow depends on third-party harnesses with Claude Code, budget for pay-as-you-go costs or start evaluating alternatives before the change takes effect.