

Weekly Review: From Vibe Coding to Agentic Engineering
Your weekly briefing on AI tutorials, tools, and developer trends

Thanks for joining us for another edition of Altered Craft’s weekly AI review for developers. This week marks a clear inflection point: the conversation around AI coding has shifted from casual experimentation to professional orchestration. The tutorials feature practitioners building compilers with 16 parallel agents and sharing hard-won adoption frameworks. A wave of model releases landed from Anthropic, OpenAI, and Alibaba. And the editorials wrestle with what this new era demands of us as engineers, and what it costs.
TUTORIALS & CASE STUDIES
Mitchell Hashimoto’s AI Adoption Journey
Estimated read time: 13 min
The creator of Terraform and Vagrant shares a six-step progression from AI skepticism to daily agentic workflows. His framework covers reproducing manual tasks with agents, deploying them during low-energy periods, outsourcing high-confidence work, and engineering project-level harnesses. Honest take: know when not to use agents.
The takeaway: Hashimoto’s progression is a practical onramp you can follow week by week, starting with low-risk tasks and building toward continuous agent operation as confidence grows.
Context Engineering for AI Coding Agents
Estimated read time: 11 min

One of Hashimoto’s key insights is investing in agent harnesses. Birgitta Böckeler explores that idea in depth, examining how context engineering shapes coding agent effectiveness using Claude Code as a primary example. Context breaks into reusable prompts, tools, and file access, each triggered by humans, LLMs, or deterministic rules. Keep context compact and build configurations gradually.
Why this matters: The agents you use are only as good as what they can see. This gives you a systematic framework for controlling that input rather than hoping for the best.
Building a C Compiler with 16 Parallel Agents
Estimated read time: 17 min
Taking context engineering to its extreme, Nicholas Carlini details how 16 autonomous Claude instances built a 100,000-line Rust C compiler capable of compiling the Linux kernel across three architectures. The project ran 2,000 sessions over two weeks at $20,000. Lessons center on airtight test harnesses, oracle-based validation, and task design for parallel agents.
What’s interesting: The real contribution here is the orchestration playbook: how to structure test validation, synchronize via git locks, and transition from independent tasks to specialized agent roles.
Build a Custom LLM Memory Layer from Scratch
Estimated read time: 12 min
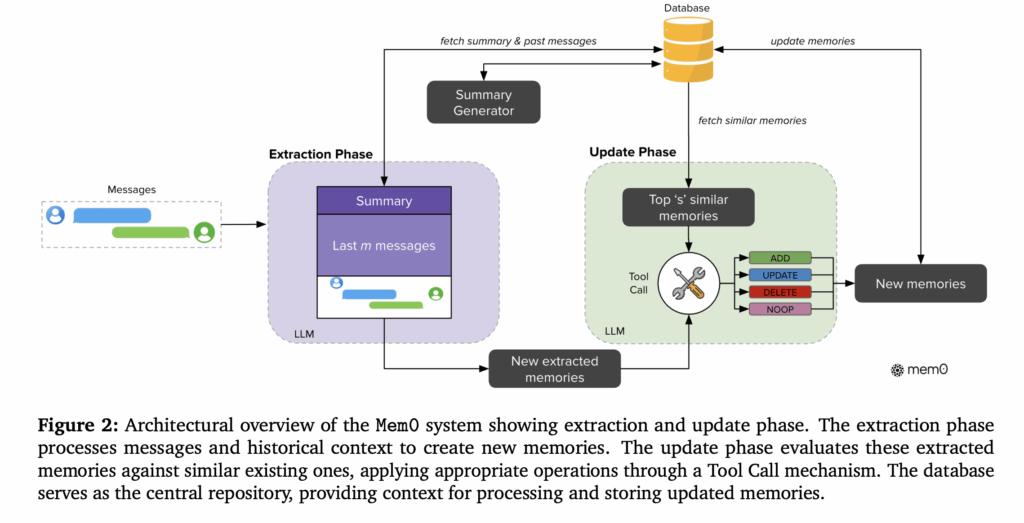
Shifting from agent orchestration to core infrastructure, and complementing our look at Clawdbot’s local-first memory architecture[1] last week, this tutorial addresses LLM statelessness across sessions. The guide walks through building an autonomous memory retrieval system that gives chat applications persistent, user-level context, covering architecture patterns for conversation state and integrating memory retrieval directly into LLM API calls.
[1] How Clawdbot Remembers Everything
What this enables: If you’re building conversational AI products, custom memory layers let you personalize interactions without relying on ever-larger context windows or third-party services.
Effectively Writing Quality Code with AI
Estimated read time: 6 min
For those building these systems, maintaining code quality remains critical. Strategies include documenting architecture decisions explicitly, marking AI-written functions with review-status comments, writing property-based tests that resist mock manipulation, and using context files like CLAUDE.md to standardize project guidance.
Key point: A concrete checklist you can adopt today. The review-status marking system for AI-written code is especially useful for teams managing mixed human/AI codebases.
TOOLS
Claude Opus 4.6 Arrives with 1M Context Window
Estimated read time: 9 min
Anthropic released Claude Opus 4.6 with a 1M token context window (beta), 128K output tokens, and improved agentic coding for large codebases. New features include agent teams, context compaction, and adaptive thinking with effort controls. Benchmarks show the top score on Terminal-Bench 2.0 and a 144 Elo advantage over GPT-5.2.
Why now: The 1M context window in an Opus-class model, combined with effort controls that let you tune intelligence vs. cost, makes this the most flexible frontier model for agentic coding workflows.
OpenAI Launches GPT-5.3-Codex
Estimated read time: 12 min
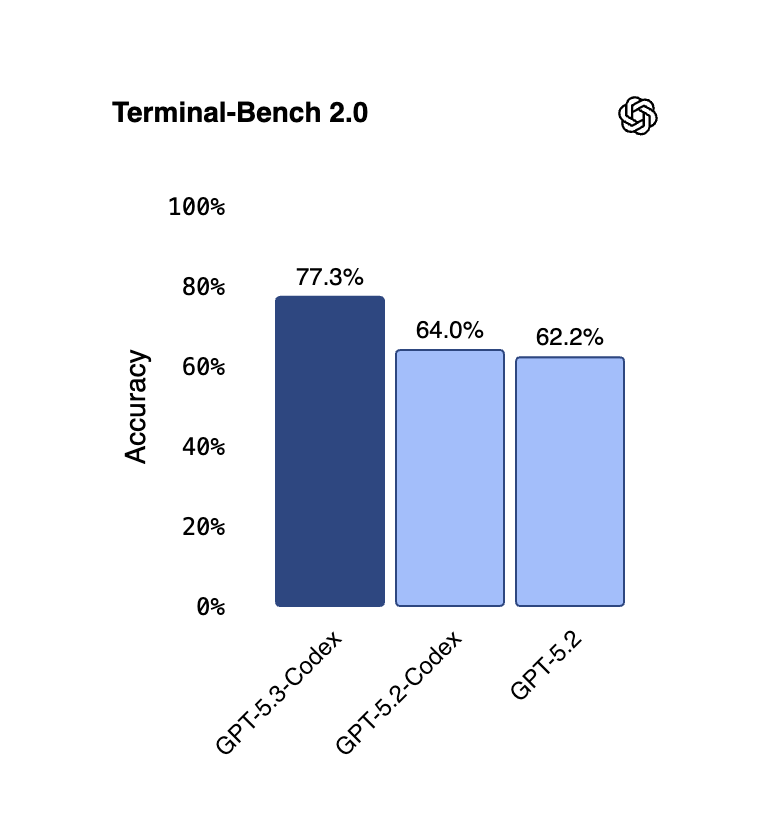
Also competing at the frontier, OpenAI released GPT-5.3-Codex, combining coding and reasoning capabilities in a single model that is 25% faster than its predecessor. It sets new highs on SWE-Bench Pro and Terminal-Bench 2.0 while using fewer tokens. Notable firsts: the model helped debug its own training, and users can steer it interactively while it works.
What’s interesting: The model extends beyond code into general knowledge work, producing slide decks, spreadsheets, and data analysis. OpenAI is positioning Codex as a full-spectrum professional agent, not just a coding tool.
Qwen3-Coder-Next: Efficient Open-Weight Coding Agent
Estimated read time: 3 min

Following our coverage of Alibaba’s frontier reasoning model Qwen3-Max-Thinking[1] last week, the Qwen team now targets the other end of the spectrum. Qwen3-Coder-Next is a 3B-active-parameter coding agent built on hybrid attention and MoE architecture. It scores over 70% on SWE-Bench Verified and matches models with 10x-20x more active parameters, excelling at long-horizon reasoning for local development.
[1] Qwen3-Max-Thinking: Alibaba’s Frontier Reasoning Model
The opportunity: A coding agent model you can run locally with competitive benchmark scores. For teams with cost constraints or data privacy requirements, this changes the calculus on self-hosted agent tooling.
Claude Code Agent Teams for Parallel Coordination
Estimated read time: 12 min
Returning to the Anthropic ecosystem, this experimental feature lets developers coordinate multiple Claude Code instances as a team with shared task lists, inter-agent messaging, and a lead orchestrating work. Unlike subagents, teammates communicate directly. Best for parallel code review, competing-hypothesis debugging, and cross-layer development.
Worth noting: This is the infrastructure behind the C compiler case study above. Agent teams move multi-session orchestration from custom scripts into a first-party, supported workflow.
GLM-OCR: Lightweight Open-Source Document Understanding
Estimated read time: 7 min
Shifting from code generation to document processing, GLM-OCR is a 0.9B parameter model ranking first on OmniDocBench V1.5 with a 94.62 score for document parsing, formula recognition, and table extraction. MIT licensed, deployable via vLLM, SGLang, or Ollama, it processes 1.86 PDF pages per second across eight languages.
What this enables: State-of-the-art document understanding at a fraction of the cost of API-based OCR. Drop it into RAG pipelines for invoices, legal docs, or technical papers without external service dependencies.
Voxtral Transcribe 2: Fast Multilingual Speech-to-Text
Estimated read time: 6 min
Also in the specialized model space, Mistral AI launched Voxtral Mini Transcribe V2 for batch processing with speaker diarization and 3-hour recording support at $0.003/minute, alongside Voxtral Realtime for sub-200ms live transcription as a 4B open-weights model under Apache 2.0. Both cover 13 languages.
The context: Sub-$0.01/minute transcription with open-weight real-time options gives developers building voice agents or meeting tools a serious alternative to proprietary APIs.
Fluid: AI-Powered VM Debugging for DevOps
Estimated read time: 4 min
Moving from models to infrastructure tooling, Fluid is a CLI tool giving SREs an AI agent for debugging production VMs through read-only investigation, sandboxed editing on cloned VMs, automatic Ansible playbook generation, and cleanup. Fixes are validated in isolation before touching production.
Why this matters: The sandbox-first approach solves the trust problem with AI in production. Test fixes on cloned VMs, then auto-generate the Ansible playbook for reproducible deployment.
NEWS & EDITORIALS
Karpathy Reflects: From Vibe Coding to Agentic Engineering
Estimated read time: 3 min
One year after coining “vibe coding,” Andrej Karpathy reflects on how the term evolved. He now prefers “agentic engineering” to describe the professional workflow where developers orchestrate AI agents with oversight rather than writing code directly. Vibe coding suited demos; agentic engineering demands rigor and accountability.
Key point: The naming shift reflects a real maturation. When the person who coined the casual term starts insisting on “engineering,” it signals the practice has earned professional expectations.
I Miss Thinking Hard
Estimated read time: 6 min
Not everyone is celebrating the shift. Building on our coverage of Anthropic’s research showing AI tools reduce learning outcomes[1] last week, a developer reflects on how they have disrupted the deep intellectual satisfaction of problem-solving. When AI provides “close enough” solutions in a fraction of the time, choosing the harder path feels irrational, yet the prolonged creative struggle that once defined engineering’s best moments is lost.
[1] AI Assistance May Reduce Coding Skills
Worth noting: An honest piece that names something many developers feel but rarely articulate. Recognizing this tension is the first step toward intentionally preserving the work that keeps your skills sharp.
The Third Golden Age of Software Engineering
Estimated read time: 25 min
Offering a longer historical lens on this tension, Grady Booch argues AI is another step up the abstraction ladder. He frames the current era as the third golden age of software engineering, following ages of algorithms and object-oriented design. Delivery pipelines face automation risk, but systems thinkers are positioned to thrive.
The takeaway: Booch’s framing is genuinely encouraging. Every past abstraction shift created more opportunity, not less, and he makes a compelling case this one will too.
The Pinhole View of AI Value
Estimated read time: 6 min
Shifting from the developer perspective to the business case, Kent Beck pushes back against measuring AI’s impact solely through headcount reduction. He identifies four value levers beyond cost cutting: expanded capacity, personalization at scale, new capabilities, and faster time-to-revenue. Optionality itself has value.
Why this matters: Next time leadership frames AI purely as a headcount play, this framework gives you a concrete vocabulary for the value your team is actually creating.
The AI Engineering Stack Explained
Estimated read time: 21 min

For a structural view of where this value gets built, Chip Huyen’s adapted book excerpt maps the three-layer architecture of modern AI applications: application development, model development, and infrastructure. The key shift: AI engineering favors prompt engineering and evaluation over traditional ML training, giving full-stack engineers new advantages.
The opportunity: If you’re a full-stack developer, this piece confirms that your skill set maps directly to AI engineering. The barrier to entry has shifted from PhD-level ML knowledge to product intuition.
The Software Factory: AI Agents Without Human Review
Estimated read time: 9 min
Taking the AI engineering stack to its most radical conclusion, Simon Willison examines StrongDM’s approach where coding agents write, test, and deploy software without human code review. They use AI-generated “Digital Twin” service clones for testing and scenario-based validation measuring satisfaction rather than boolean pass/fail.
What’s interesting: Even if fully autonomous coding isn’t your goal, the Digital Twin pattern and scenario-based validation are techniques you can adopt independently for testing AI-generated code.