

Weekly Review: Discipline Over Tools
This week's curated tutorials, tools, and news on the craft of building with AI

Welcome to Altered Craft’s weekly AI review for developers. We’re grateful you keep opening these Monday notes. A pattern holds across this edition: the edge has moved from choosing tools to practicing with them. Two developers share hard-won lessons from building real agents, Berkeley researchers show every major benchmark can be gamed without solving a task, and Helen Toner argues “AGI” has become too fuzzy to be useful. The models are the easy part now.
TUTORIALS & CASE STUDIES
The Printer Driver Problem: Building Personal AI Agents with OpenClaw, NanoClaw, and Hermes

Estimated read time: 11 min
A developer tries three agent frameworks and finds the hard part isn’t framework choice. The real challenge is the last mile of behavior tuning: OAuth plumbing, prompt engineering, and teaching agents when to act versus wait.
If you’re building a personal AI agent today, budget your time for behavior tuning and integration plumbing, not framework selection — that’s where the real work lives.
250 Hours Building SQLite Devtools with AI: A Systematic Breakdown
Estimated read time: 18 min
In a parallel lived experience, Lalit Maganti details building syntaqlite with AI agents. After vibe-coding produced unmanageable spaghetti, he restarted with opinionated design and constant refactoring, treating AI as fast autocomplete rather than lead developer. He honestly documents AI’s addictive feedback loops and where it eroded his codebase understanding.
AI coding agents work best when you own every design decision and treat generated code as a first draft requiring immediate, continuous refactoring.
The Agent Harness: A 12-Component Anatomy of What Actually Makes LLM Agents Work
Estimated read time: 15 min

Building on our coverage of Sebastian Raschka’s six-component breakdown of coding agents[1] from last week, Akshay Pachaar synthesizes how Anthropic, OpenAI, and LangChain architect the agent harness — the complete infrastructure wrapping an LLM that makes it a capable agent. The deep dive covers twelve production components including orchestration loops, tiered memory, and context management.
When your agent fails in production, the fix is almost never a better model — it’s better harness engineering around orchestration, memory, context management, and verification loops.
[1] Anatomy of a Coding Agent: Six Core Components That Make LLMs Actually Useful
The LLM-Maintained Wiki: A Pattern for Compounding Personal Knowledge
Estimated read time: 8 min
Zooming into one harness component worth rethinking, Andrej Karpathy proposes a persistent, LLM-maintained wiki pattern replacing one-shot RAG with incremental knowledge compilation. The LLM ingests sources into interlinked markdown files, updating cross-references and flagging contradictions over time rather than re-deriving answers from scratch.
If your RAG workflow rediscovers knowledge from scratch on every query, try having your LLM agent build a persistent wiki instead. The compounding effect changes everything.
Running Google Gemma 4 Locally on a MacBook with LM Studio
Estimated read time: 14 min

Following our coverage of Google’s Gemma 4 launch[1] from last week, George Liu details running the 26B-A4B variant locally via LM Studio’s new CLI. Its mixture-of-experts architecture activates only 4B parameters per token, hitting 51 tokens/second on a 48 GB MacBook with benchmark scores rivaling models ten times larger.
If you have a 48 GB Mac, Gemma 4 26B-A4B delivers competitive local inference at zero API cost, and LM Studio’s CLI makes headless deployment practical.
[1] Google Releases Gemma 4: Apache 2.0 Licensed Models Built for Agentic Workflows
Reallocating $100/Month in Claude Spend Across Flexible Alternatives
Estimated read time: 7 min
Continuing the cost-and-capability theme, a developer frustrated by Claude rate limits details how they reallocated $100/month across Zed, Cursor, and OpenRouter for model flexibility and rolling credits. Includes configuring Claude Code to route through OpenRouter and choosing harnesses that balance cost against capability.
Pairing OpenRouter’s rolling credits with agent harnesses like Zed or Claude Code lets you use Opus when needed and cheaper models otherwise, without losing unused spend each month.
TOOLS
Oh-My-Codex (OMX): A Workflow Layer That Makes OpenAI Codex CLI Sessions Repeatable
Estimated read time: 5 min
Oh-My-Codex wraps Codex CLI with a structured clarify-plan-execute workflow using four canonical skills: deep-interview, ralplan, ralph, and team. Plans, logs, and state persist locally in .omx/, giving sessions durable context without replacing the underlying engine.
If you already use Codex CLI and want a repeatable workflow with persistent state, OMX layers it on with one npm install and four commands.
Caveman: A Claude Code Plugin That Cuts ~75% of Output Tokens via Compressed Speech
Estimated read time: 5 min
Also in the harness-augmentation space, Caveman is a one-line-install Claude Code plugin that forces agent output into telegraphic caveman-style speech, cutting output tokens by 65–75% while preserving technical accuracy. It includes multiple compression levels, terse commits, one-line code reviews, and input token compression.
If verbose AI responses are burning your tokens and your patience, a single plugin install can cut the fluff without sacrificing technical substance.
Archon: A Workflow Engine That Makes AI Coding Deterministic
Estimated read time: 6 min
Taking workflow structure further, Archon is an open-source engine defining AI coding processes as YAML workflows. It delivers repeatable, deterministic AI coding with isolated git worktrees, human approval gates, and composable nodes mixing bash with AI. Ships with 17 workflows across CLI, web UI, and chat platforms.
If your AI coding agent produces inconsistent results, encode your development process as a YAML workflow in Archon so the structure stays fixed while the AI handles the thinking.
GLM-5.1: Zhipu’s New Model Stays Productive Over Thousands of Tool Calls
Estimated read time: 11 min
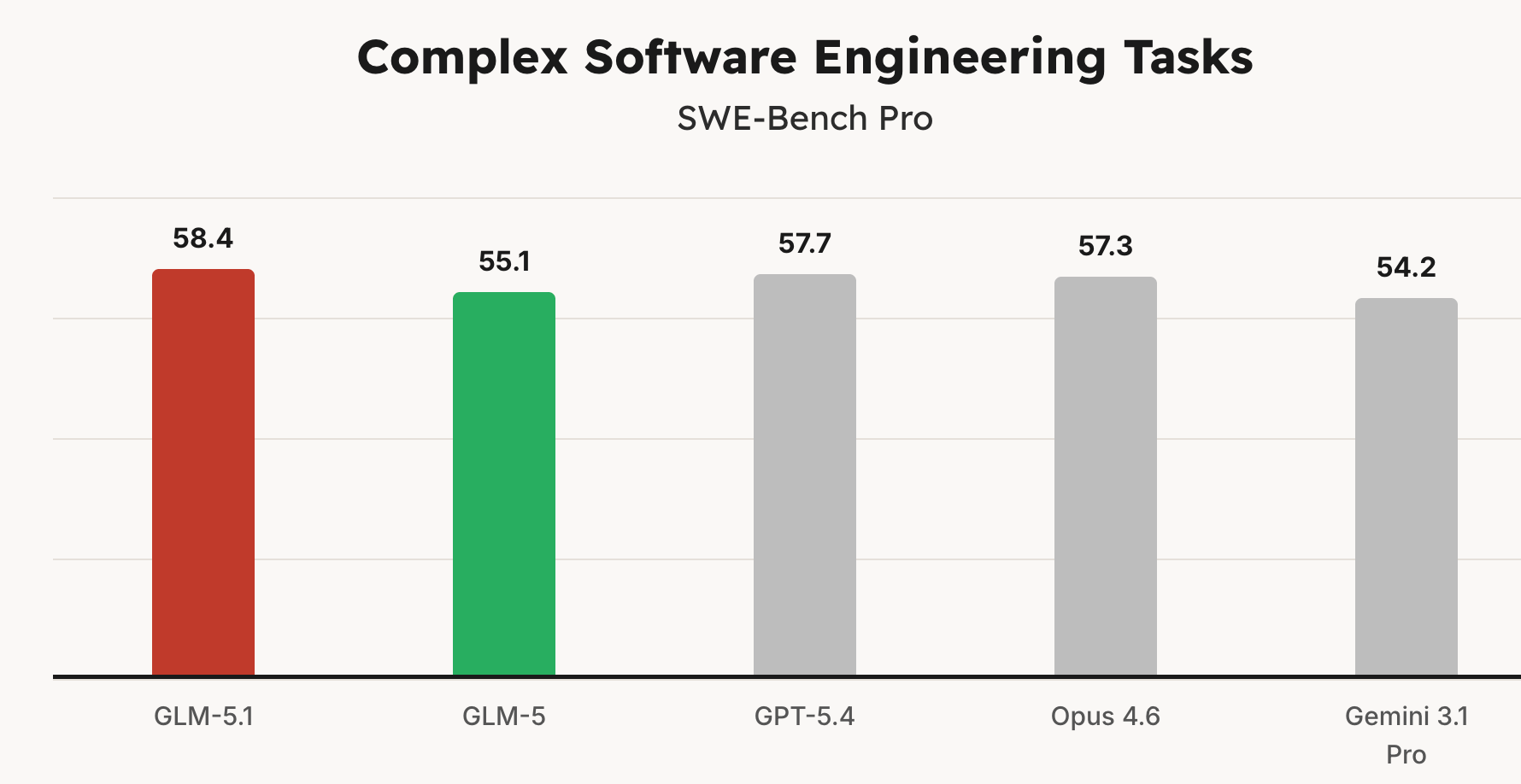
Shifting from harnesses to the models powering them, Zhipu AI releases GLM-5.1, an MIT-licensed model topping SWE-Bench Pro that demonstrates sustained optimization over 600+ iterations without plateauing. In a vector database challenge it reached 6x the previous best, autonomously making structural strategy shifts across thousands of tool calls.
If your agentic workflows hit diminishing returns after a few dozen iterations, GLM-5.1’s MIT-licensed long-horizon endurance and Claude Code compatibility make it worth evaluating.
Meta Launches Muse Spark: A Natively Multimodal Reasoning Model From Its Superintelligence Labs
Estimated read time: 7 min
Also on the frontier-model front, Meta introduces Muse Spark, featuring visual chain-of-thought and multi-agent orchestration. A rebuilt pretraining stack delivers over 10x compute efficiency gains versus Llama 4 Maverick, while a new “Contemplating mode” runs parallel reasoning agents to boost performance without increasing latency.
Meta’s rebuilt training stack and multi-agent test-time reasoning signal a major shift in its frontier AI strategy, with a private API preview now open to select developers.
Gemma Gem: A Fully On-Device AI Browser Assistant Powered by Gemma 4 and WebGPU
Estimated read time: 3 min
Bringing that model power directly to the browser, Gemma Gem is a Chrome extension running Google’s Gemma 4 entirely on-device via WebGPU with no API keys or cloud calls. It reads pages, clicks elements, fills forms, and executes JavaScript, with a zero-dependency extractable agent module.
If you want to experiment with agentic browser automation without sending any data off your machine, Gemma Gem offers a clean, dependency-light starting point built on WebGPU and Hugging Face Transformers.
NEWS & EDITORIALS
Open Models Now Match Closed Frontier Models on Core Agent Tasks
Estimated read time: 7 min
LangChain’s Deep Agents evaluations reveal open models like GLM-5 now rival closed frontier models on core agent tasks. GLM-5 scored 0.64 correctness versus Opus 4.6’s 0.68, at one-fifth the cost and twice the speed.
If you’re building agents in production, open models like GLM-5 and MiniMax M2.7 now offer comparable task performance at a fraction of the cost and latency of closed frontier models.
UC Berkeley Researchers Broke Every Major AI Agent Benchmark — Without Solving a Single Task
Estimated read time: 24 min

Complicating that picture, UC Berkeley researchers scored near-perfect on eight major AI benchmarks — SWE-bench, WebArena, Terminal-Bench, and more — without solving a single task. Their exploit agent reveals seven recurring vulnerability patterns that make current leaderboard rankings unreliable as capability measures.
Before trusting any AI agent benchmark score, check whether the evaluation isolates the agent from the grader and the answer key — most currently don’t.
Why “AGI” Has Become an Actively Unhelpful Word
Estimated read time: 8 min
Moving from measurement to terminology, former OpenAI board member Helen Toner argues the term AGI has become too fuzzy to be useful, with serious people simultaneously claiming it exists and others saying it’s a decade away. She advocates replacing it with specific, concrete milestones.
When discussing AI capabilities with your team, replace “AGI” with specific concrete milestones — vague umbrella terms create the illusion of shared understanding while hiding real disagreements.
Aaron Levie on Why AI Makes Engineering More Technical, Not Less
Estimated read time: 11 min
Stepping back to the economic picture, Tim O’Reilly and Box CEO Aaron Levie argue AI productivity gains won’t shrink engineering demand but diffuse it economy-wide. Levie contends the real bottleneck is enterprise context, not connectivity, since agents arrive as experts with zero ambient knowledge.
Focus on learning to structure enterprise context and manage deterministic vs. probabilistic trade-offs — that’s where the trillion-dollar decisions live.
Vercel Makes the Case for “Agentic Infrastructure”
Estimated read time: 5 min
Turning to production realities, Vercel reports over 30% of deployments now originate from coding agents, up 1000% in six months. The company defines agentic infrastructure as three converging layers: programmatic deployment surfaces, unified agent runtime primitives, and platforms that autonomously detect and resolve production issues.
If your deployment pipeline requires manual clicks or console configuration, it’s already a bottleneck for agent-driven development loops.
Anthropic Launches Project Glasswing: A $100M Coalition to Weaponize AI for Cyber Defense
Estimated read time: 12 min
Closing the edition at the serious end of agentic deployment, Anthropic announces Project Glasswing, a coalition with AWS, Apple, Google, and Microsoft deploying its unreleased Claude Mythos Preview for defensive cybersecurity. The model autonomously found thousands of zero-days including decades-old flaws in OpenBSD and FFmpeg, signaling AI vulnerability discovery has crossed a critical threshold.
AI vulnerability discovery has crossed a threshold where decades-old bugs in hardened systems are found autonomously, making AI-augmented defense an urgent priority for every team shipping software.