

Weekly Review: Defining the Partnership with agents
The week's curated set of AI tutorials, tools, and perspectives on the evolving developer-agent relationship

Thanks for joining us for another Altered Craft weekly AI review for developers. We appreciate every reader who makes Monday mornings a little more intentional. This week’s collection circles a central question: as agents grow more capable and autonomous, what exactly does the developer’s role become? You’ll find collaboration frameworks from Thoughtworks, a sobering SQLite case study on AI code quality, GPT-5.4’s leap into computer use, and honest examinations of how the profession itself is changing.
TUTORIALS & CASE STUDIES
Five Patterns for Productive AI Collaboration
Estimated read time: 19 min
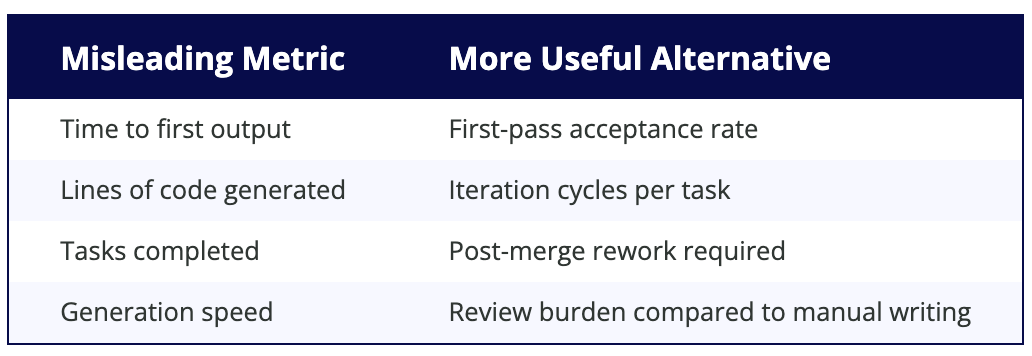
Rahul Garg proposes reframing AI coding assistants from “tools” to “teammates” through five patterns: Knowledge Priming, Design-First Collaboration, Sensible Defaults, Context Anchoring, and a Feedback Flywheel. The article argues that reducing friction requires shared vocabulary and architecture vision between humans and AI systems.
The takeaway: These five patterns offer a concrete framework for teams frustrated by the generate-review-fix cycle, shifting the focus from faster output to higher first-pass acceptance rates.
Positioning Humans in AI Development Loops
Estimated read time: 13 min

Also from Thoughtworks, Morris presents three models for human-AI collaboration: outside the loop (vibe coding), inside the loop (manual review), and on the loop (recommended). The preferred approach positions developers as harness engineers who design systems guiding agent behavior rather than inspecting outputs directly.
What’s interesting: The “on the loop” model reframes engineering work around designing guardrails and quality systems, a role that grows more valuable as agents handle more implementation.
Why LLM-Generated Code Compiles but Fails
Estimated read time: 22 min
But what happens when these collaboration models fall short? An LLM-generated Rust reimplementation of SQLite compiles and passes tests, yet performs primary key lookups 20,171 times slower than the original. The article demonstrates how LLMs optimize for plausibility over correctness, missing optimizations discovered through decades of profiling real workloads.
Key point: A compelling argument for defining acceptance criteria before generating code. Performance benchmarks and integration tests catch what compilation and unit tests miss entirely.
Replacing Code Review with Spec-Driven Development
Estimated read time: 13 min
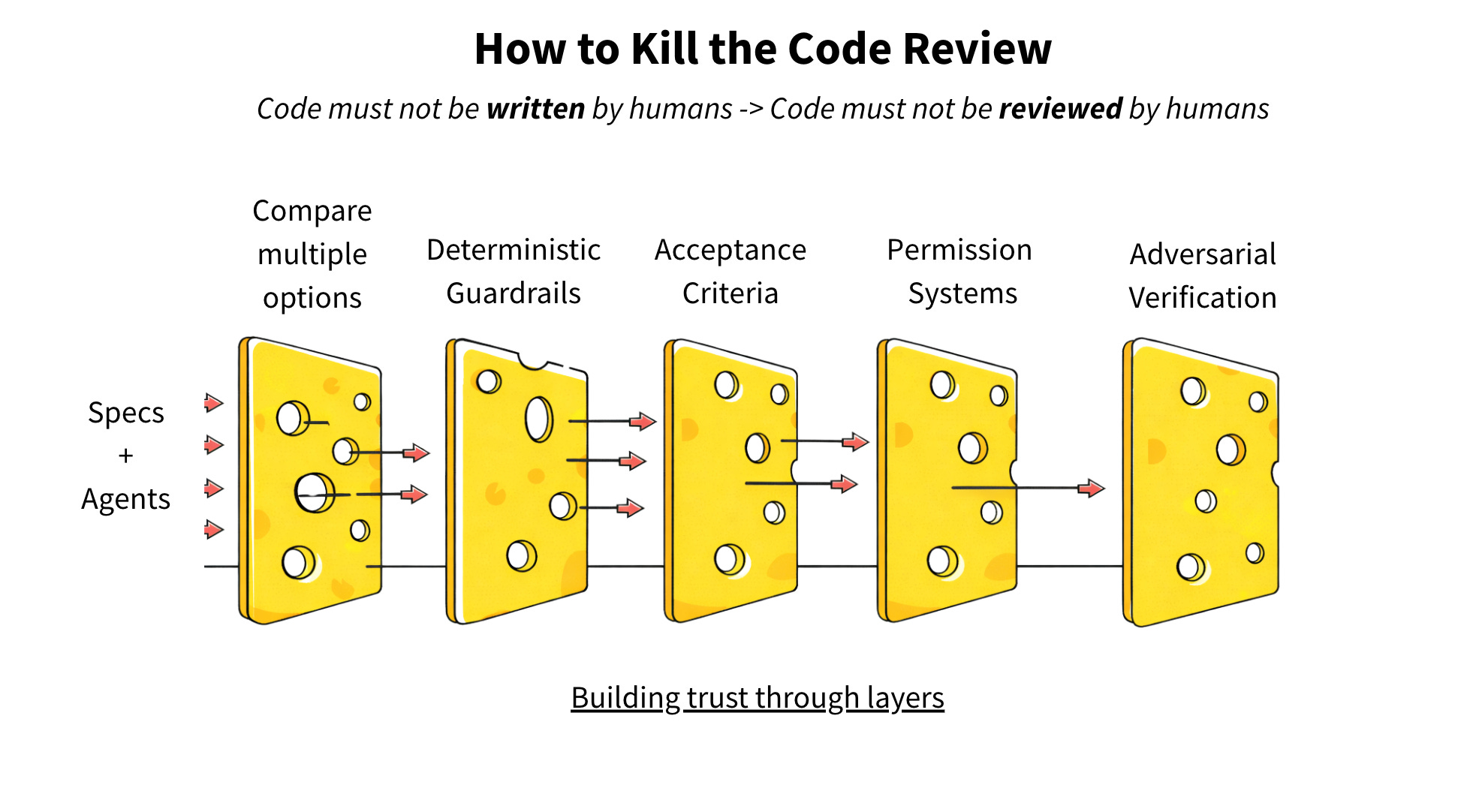
Addressing this code quality challenge, Jain argues that manual code review cannot scale with AI-generated volumes, citing a 91% increase in PR review time for high-adoption teams. He proposes a five-layer trust model replacing human review with deterministic guardrails, moving human judgment upstream to defining specifications.
The opportunity: If your team is drowning in PR reviews, this framework offers a practical path forward: define success criteria upfront and let automated verification replace opinion-based code inspection.
From Manual Prompting to Autonomous Agent Systems
Estimated read time: 16 min
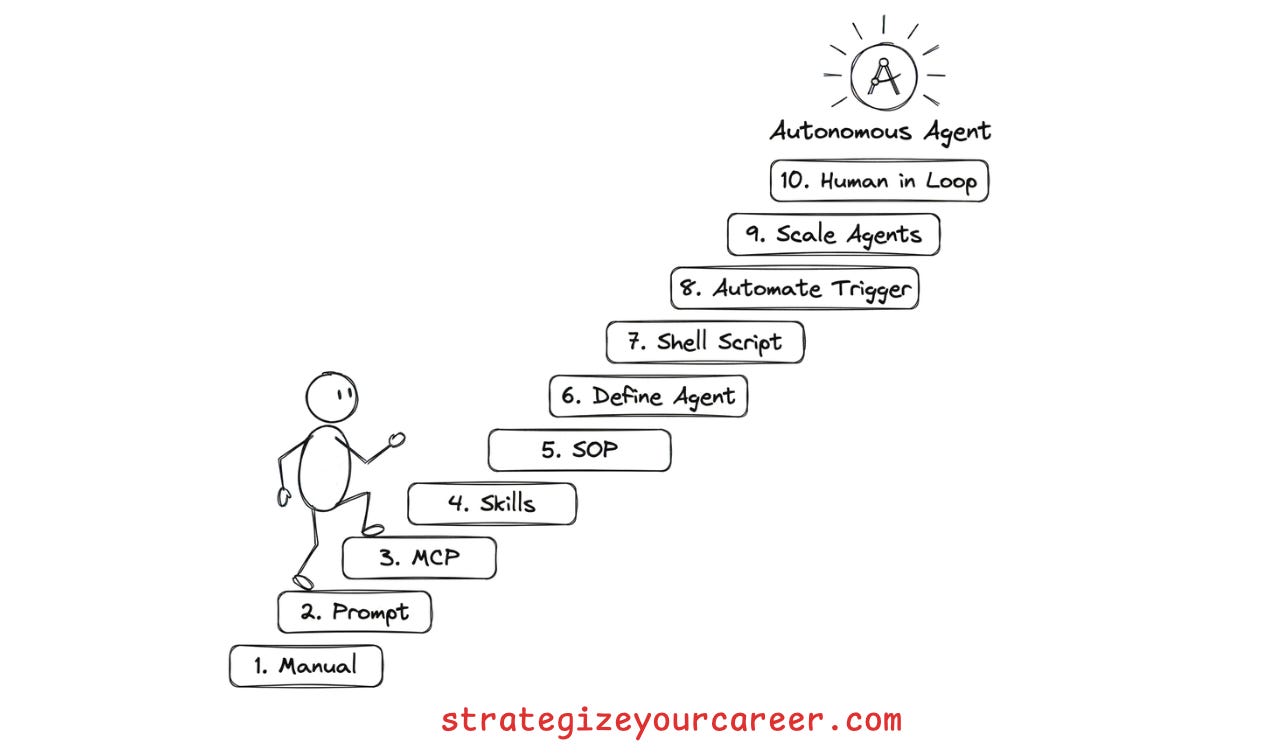
Moving from agent oversight to agent construction, Amazon engineer Fran Soto outlines a ten-step progression from reactive chat-based prompting to building autonomous multi-agent systems. Steps cover integrating MCP servers, creating agent SOPs, automating triggers with cron jobs, and scaling to specialized agent teams.
Why this matters: A genuinely actionable guide that takes you from “I use ChatGPT sometimes” to running autonomous agents on your codebase, with each step building on the last.
Why XML Tags Define Claude’s Advantage
Estimated read time: 5 min
On the prompting side, Lethuillier argues that Claude’s effectiveness stems from making XML tags first-class citizens in its framework. Drawing parallels between delimiters in programming languages, bacterial DNA, and Homeric verse, the article presents a universal principle: languages require markers to signal transitions between expression levels.
Worth noting: If you’ve been on the fence about XML-structured prompts with Claude, this linguistic deep dive explains why they consistently improve output quality over plain-text instructions.
TOOLS
GPT-5.4 Launches with Native Computer Use
Estimated read time: 25 min
OpenAI’s most capable frontier model combines reasoning, coding, and agentic workflows with native computer-use capabilities and 1M token context. GPT-5.4 achieves 75% on OSWorld (surpassing human performance at 72.4%), introduces tool search for large ecosystems, and uses 47% fewer reasoning tokens than GPT-5.2.
What this enables: Native computer use plus 1M token context opens the door to agents that can plan, execute, and verify multi-step workflows across applications without human intervention.
India’s Open-Source Reasoning Models Go Global
Estimated read time: 18 min
Also in the model release space, Sarvam AI open-sources two Mixture-of-Experts reasoning models trained entirely in India: a 30B for real-time deployment and a 105B for complex reasoning. The 105B scores 98.6 on Math500 and 88.3 on AIME25, competing with frontier models at a fraction of training compute.
The context: Open-weight models with frontier-competitive reasoning keep expanding options for teams that need to self-host, fine-tune for specialized domains, or maintain independence from any single vendor.
Cursor Launches Always-On Agent Automations
Estimated read time: 13 min
Putting models like these to work, Cursor introduces Automations: always-on agents triggered by schedules, Slack messages, GitHub PRs, or PagerDuty incidents. Agents spin up in cloud sandboxes, follow custom instructions with configured MCPs, and learn from previous runs. Use cases include security review, PR risk assessment, and incident response.
Why now: This bridges the gap between “AI that helps when you ask” and “AI that works while you sleep,” turning recurring chores like security audits and triage into automated workflows.
OS-Enforced Sandbox for Untrusted AI Agents
Estimated read time: 5 min
With agents running autonomously, security becomes critical. Continuing our look at agent security patterns from Vercel and NanoClaw[1] last week, nono provides kernel-level capability sandboxing for AI agents on macOS and Linux, built by the team behind Sigstore. It implements deny-by-default security with atomic filesystem snapshots for rollback, cryptographic audit trails, and runtime permission management. SDKs support Python and TypeScript.
[1] Five Security Patterns for AI Agent Architectures
Worth noting: A proper sandboxing layer for teams experimenting with autonomous agents. The rollback and audit capabilities make it practical to give agents real system access with confidence.
Slash LLM Token Usage with Smart Compression
Estimated read time: 9 min

Shifting to developer workflow efficiency, RTK is a single Rust binary that reduces token consumption by 60-90% during AI-assisted development through smart filtering, grouping, and deduplication of command output. It transparently intercepts shell commands via hooks, compressing results before they reach the LLM context window with sub-10ms overhead.
The takeaway: If you’re hitting context limits or watching API costs climb during long coding sessions, this is a drop-in solution that works with your existing tools and workflows.
Unified CLI for Google Workspace and Agents
Estimated read time: 9 min
Also on the CLI front, Google releases a unified command-line tool for all Workspace services, built for humans and AI agents. The CLI dynamically generates commands from Google’s Discovery Service at runtime, includes 100+ agent skills, and supports structured JSON output with multiple auth workflows.
Key point: Dynamic command generation from Google’s live API definitions means the tool stays current without manual updates, making it especially useful for building agents that interact with Workspace.
Serverless Data Ingestion for Vector Search
Estimated read time: 6 min
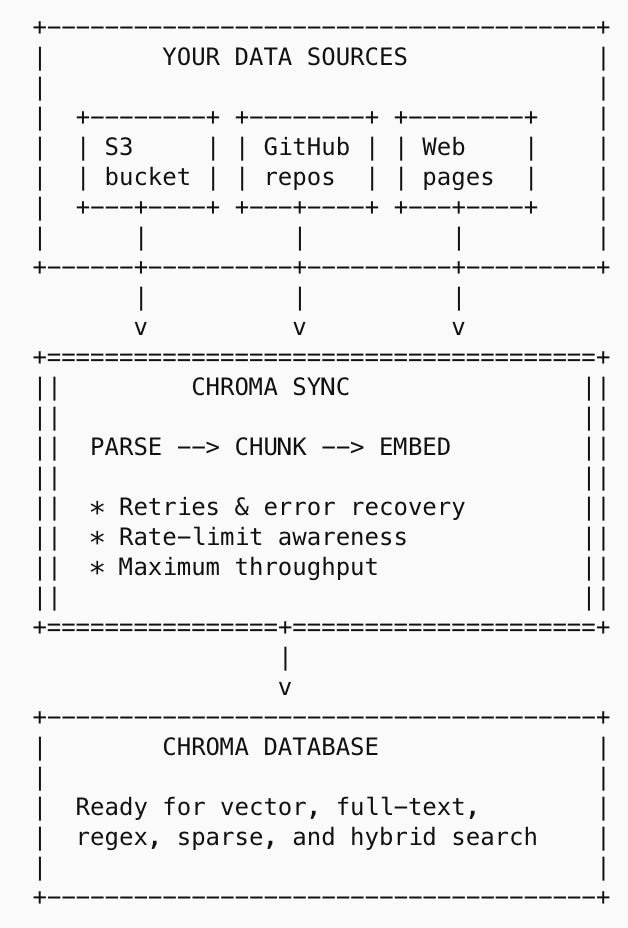
Turning to data infrastructure, Chroma Sync offers serverless data ingestion connecting S3, GitHub, and websites to Chroma Cloud. The platform handles parsing, chunking (using Tree-sitter for code), and embedding automatically. It supports incremental updates and syntax-aware code chunking respecting function boundaries, with pricing starting at $0.04 per GB.
Why this matters: RAG pipelines often stall at the ingestion step. This removes the parsing and chunking burden entirely, letting you focus on retrieval quality and application logic.
NEWS & EDITORIALS
Architecture Skills Now Outweigh Code Writing
Estimated read time: 9 min
A developer reflects on how AI has shifted the core engineering skill from writing code to understanding architecture and system design. Foundational computer science knowledge has become more critical than ever: experienced engineers find their intuition compounds AI capabilities, while barriers to entry have lowered for newcomers.
What’s interesting: Your deep system knowledge is an accelerant, not a redundancy. The engineers who understand architectural trade-offs are the ones getting the most leverage from AI tools.
AI Eased Code Writing but Strained Engineering
Estimated read time: 16 min
Expanding on this shifting landscape, Turkovic presents a central paradox: while AI accelerated code writing, the overall experience of being an engineer has become harder. 67% of developers report spending more time debugging AI code, entry-level hiring fell 25%, and expanding role scope without boundaries is driving burnout.
Worth reading if: you’re a team lead navigating the tension between faster output and sustainable engineering culture. The recommendations for leaders and individual engineers are practical and specific.
Anthropic Measures AI’s Real Labor Market Impact
Estimated read time: 16 min
Backing up these concerns with data, Anthropic researchers introduce “observed exposure,” combining theoretical AI capabilities with real-world usage. Key finding: actual labor market coverage remains a fraction of what is feasible. No systematic unemployment surge has emerged, though the study flags reduced hiring of younger workers in exposed occupations.
The context: The gap between theoretical AI exposure and actual adoption is enormous, which suggests the disruption timeline is longer and more navigable than popular narratives imply.
Cursor Maps Three Eras of AI Coding
Estimated read time: 9 min

Shifting from impact analysis to industry direction, Cursor’s leadership describes the evolution from Tab autocomplete to synchronous agents to autonomous cloud agents tackling larger tasks over longer timescales. Within their team, 35% of merged PRs originate from cloud agents, and agent adoption has grown 15-fold annually.
Why now: 35% of PRs from autonomous agents is a striking signal. The developer role is visibly shifting from writing code to decomposing problems and reviewing agent-generated artifacts.
Microsoft’s Compact Model Challenges Reasoning Giants
Estimated read time: 22 min
Also charting the technical frontier, Microsoft releases Phi-4-reasoning-vision-15B, a compact open-weight multimodal model that matches systems many times its size using a fraction of training data. Trained on roughly 200B tokens (versus competitors’ 1T+), it selectively applies chain-of-thought reasoning only where beneficial and excels at UI navigation.
The opportunity: A 15B model with strong vision and reasoning opens real possibilities for on-premise deployment, edge inference, and cost-effective agentic workflows where frontier models are impractical.
CLIs Beat MCP for AI Tool Integration
Estimated read time: 13 min
Following our coverage of Andrej Karpathy’s rallying cry to build CLI-first for agents[1] last week, Holmes argues that CLIs outperform the Model Context Protocol for AI tool integration. CLIs offer superior debuggability, composability, and authentication since developers can run identical commands to verify agent behavior. MCP adds process management overhead and coarse permission controls without improving security.
[1] Build for Agents: Karpathy on CLI-First Products
Worth noting: Whether you agree or not, the core argument resonates: good CLIs serve both humans and agents, while MCP often introduces more friction than it removes.