

Weekly Review: Beyond Model Intelligence
Your weekly briefing on AI tutorials, tools, and developer trends

Welcome back to Altered Craft's weekly AI review for developers. We're grateful you continue to make this part of your Monday. This week carries a unifying thread: the real gains in AI development are increasingly found in the infrastructure surrounding the model, not the model itself. Tutorials cover everything from edit format breakthroughs to token cost strategies, while open-source models from MiniMax and Z.ai push close to frontier performance. The editorials offer an honest look at AI-accelerated burnout and what benchmarks can no longer tell us.
TUTORIALS & CASE STUDIES
A Systematic Framework for AI-Assisted Development
Estimated read time: 25 min
This comprehensive guide introduces compound engineering, a methodology where each unit of work makes subsequent tasks easier. Built around a four-step Plan, Work, Review, and Compound loop, it advocates spending 80% of time on planning and review, with 26 specialized review agents and progressive adoption stages.
The takeaway: A concrete system for making AI development cumulative rather than repetitive, so every project leaves you better equipped for the next one.
How Claude Code Made TUI Development Trivial
Estimated read time: 8 min
Seeing agentic development in action, Hatchet’s Alexander Belanger built a fully functional terminal UI in two days using Claude Code and the Charm ecosystem. Key enablers included tmux capture-pane for automated testing, an OpenAPI spec for clean API integration, and an ASCII graph renderer discovered on GitHub.
What’s interesting: A practical before-and-after showing exactly which development patterns made agentic coding faster than going solo, not just in theory but in a shipped product.
Twelve Ways to Customize Your Claude Code
Estimated read time: 6 min
For developers looking to optimize their own setup, the original developer of Claude Code shares twelve customization tips for Claude Code, from terminal themes and vim mode to custom agents, hooks, and permission pre-approvals. With 37 settings and 84 environment variables, nearly every behavior is configurable.
The opportunity: Most developers use Claude Code with defaults. These customizations can meaningfully improve your daily workflow with minimal setup effort.
Inside Claude Code’s Six-Stage Insights Pipeline
Estimated read time: 11 min
Also in the Claude Code ecosystem, the /insights command runs a six-stage analysis pipeline examining your interaction history across sessions. Using Claude Haiku, it extracts structured facets including goals, satisfaction levels, and friction points, then synthesizes everything into an interactive HTML dashboard.
Worth noting: Understanding how the tool analyzes your work patterns helps you use it more intentionally and identify blind spots in your AI-assisted workflow.
Anthropic’s Complete Guide to Building Claude Skills
Estimated read time: 30 min
Taking Claude Code customization further, Anthropic’s official guide covers everything from planning to distribution for building skills that customize Claude’s workflows. Skills are instruction folders that teach Claude repeatable tasks. The guide offers standalone and MCP-enhanced paths, with practical patterns and troubleshooting tips.
What this enables: You can package your best prompting patterns into reusable, shareable skills, turning one-off workflows into team-wide productivity gains.
Building Long-Running Agents with OpenAI Primitives
Estimated read time: 9 min
Shifting to the OpenAI ecosystem, OpenAI details three primitives for building production agents: Skills, Shell, and server-side Compaction. Skills function as versioned playbooks with routing logic, Shell enables real terminal execution inside hosted containers, and Compaction manages context windows during long runs.
Key point: Both Anthropic and OpenAI are converging on similar agent architecture patterns, suggesting these building blocks are becoming industry standard for production deployments.
Why Edit Format Matters More Than Model Intelligence
Estimated read time: 9 min
Regardless of which platform you choose, and complementing our discussion of Birgitta Böckeler’s context engineering framework[1] from last week, Can Boluk argues coding agent performance is bottlenecked by the “harness” between LLM output and file edits, not model capability. His “hashline” format improved 15 models without training. Grok Fast 1 jumped from 6.7% to 68.3% success rate, with output tokens dropping roughly 20%.
[1] Context Engineering for AI Coding Agents
Why this matters: If you’re building coding tools or evaluating agents, the infrastructure around the model may matter more than the model itself.
Thirteen Strategies to Cut Your LLM Token Costs
Estimated read time: 16 min
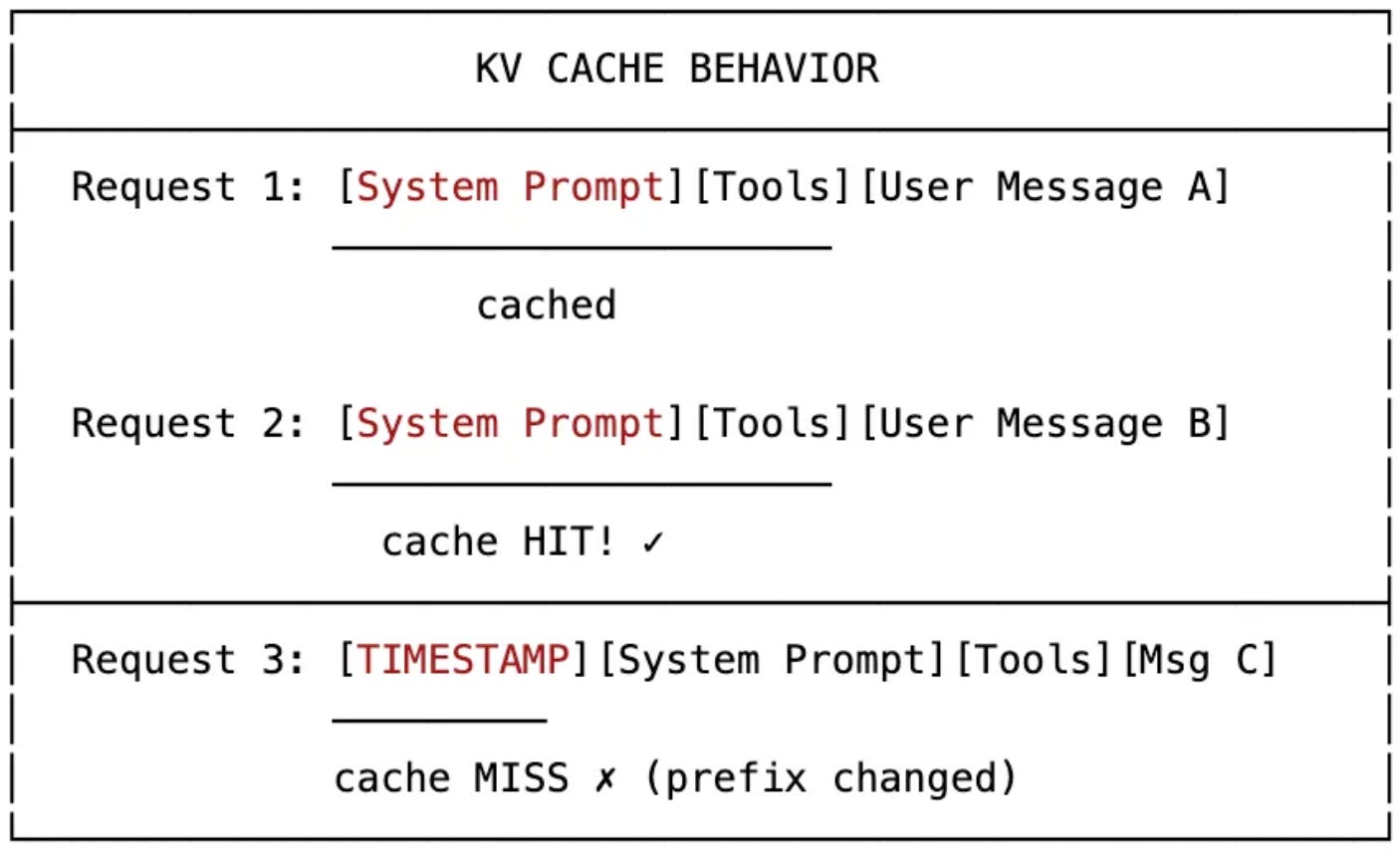
On the cost side of agent infrastructure, Nicolas Bustamante offers 13 practical strategies for managing LLM context window costs. Key tactics include stable prefixes for KV cache hits, storing tool outputs in the filesystem (which cut agent tokens by 46.9%), and delegating to cheaper subagents.
The opportunity: With output tokens costing 5x input tokens, even small optimizations compound significantly. These are production-tested techniques you can apply immediately.
TOOLS
OpenAI’s Ultra-Fast Codex Spark Hits 1000 Tokens/Second
Estimated read time: 8 min
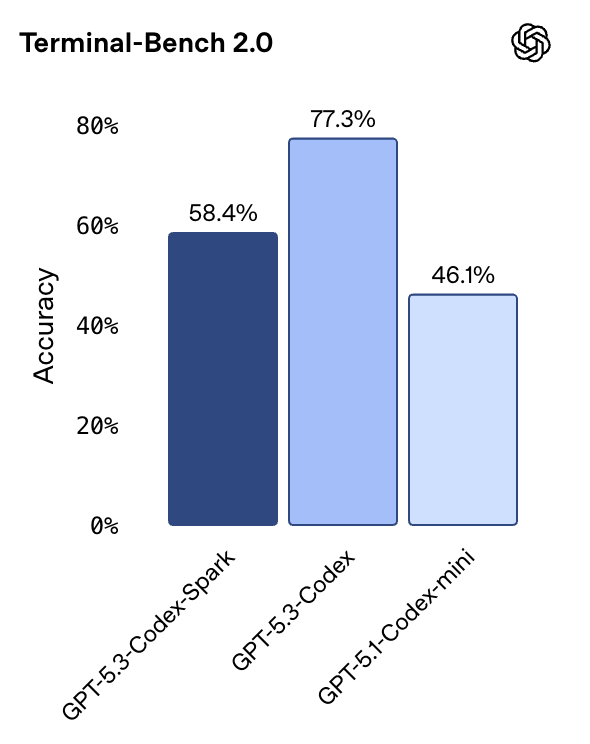
OpenAI introduces GPT-5.3-Codex-Spark, their first model optimized for real-time coding, powered by Cerebras’ Wafer Scale Engine 3 and delivering over 1,000 tokens per second. Available as a research preview for ChatGPT Pro users, Spark features a 128k context window and complements longer-horizon Codex tasks with near-instant editing.
Why now: Speed has become the new differentiator. Interactive responsiveness matters as much as raw capability when it directly affects developer flow.
Gemini 3 Deep Think Sets New Reasoning Records
Estimated read time: 5 min
Also from a major lab this week, Google releases Gemini 3 Deep Think, a specialized reasoning mode targeting science, research, and engineering. Benchmarks are striking: 48.4% on Humanity’s Last Exam, 84.6% on ARC-AGI-2, and 3455 Elo on Codeforces, with first-time API availability.
What’s interesting: Deep Think’s strength in scientific reasoning and competition programming suggests specialized reasoning modes are becoming the next frontier beyond general-purpose models.
MiniMax M2.5 Matches Frontier Models at 1/20th Cost
Estimated read time: 13 min
On the open-source front, MiniMax released M2.5, an open-source model using Mixture of Experts (230B parameters, 10B active) that approaches Claude Opus 4.6 on SWE-Bench Verified at roughly 1/20th the cost. At $0.15 per million input tokens, it already handles 30% of internal tasks at MiniMax.
The context: Open-source models reaching frontier-adjacent performance at a fraction of the cost changes the build-vs-buy calculus for teams running high-volume inference workloads.
GLM-5 Brings Agentic Engineering to Open Source
Estimated read time: 9 min
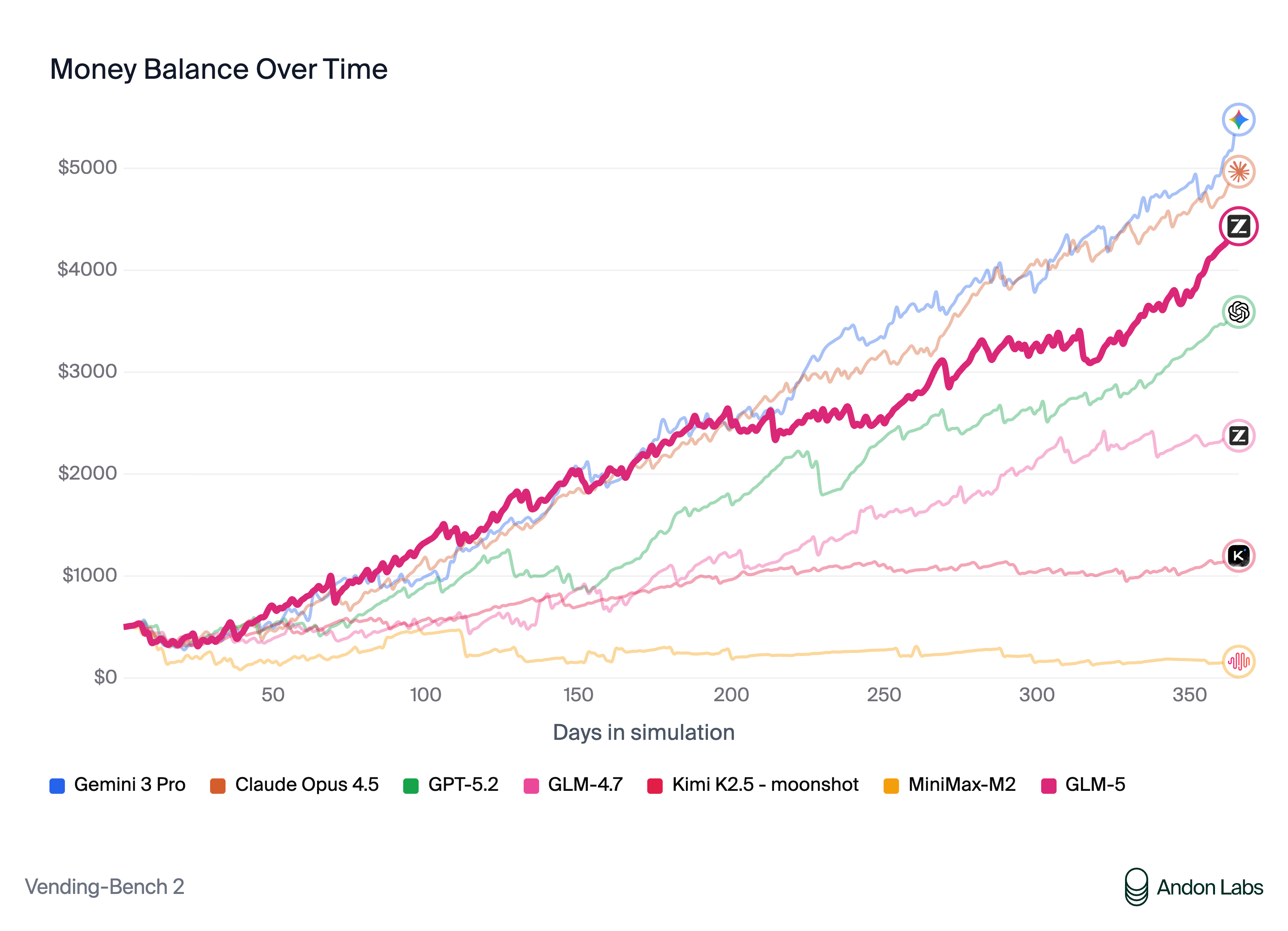
Also targeting the open-source frontier, Z.ai launches GLM-5, a 744B-parameter model (40B active via MoE) targeting complex systems engineering and long-horizon agentic tasks. It achieves 77.8% on SWE-bench Verified and ships with Claude Code compatibility, document generation, and MIT-licensed weights.
Worth noting: Two open-source models approaching frontier performance in the same week signals that the gap between proprietary and open-source is closing faster than expected.
Cursor’s Composer 1.5 Scales Reinforcement Learning 20x
Estimated read time: 4 min
Shifting from models to coding tools, Cursor announces Composer 1.5, an agentic coding model built by scaling reinforcement learning 20x, with post-training compute now exceeding pretraining. It generates “thinking tokens” to reason about codebases and uses self-summarization to continue exploring when context limits are reached.
Key point: Cursor investing more compute in post-training than pretraining reflects a broader industry shift toward specialization over general capability.
Entire CLI Captures AI Agent Context Per Commit
Estimated read time: 3 min
For teams using these coding agents daily, Entire is an open-source CLI backed by a $60M seed round that captures AI agent sessions on every push. Each commit gets a “checkpoint” pairing the code change with the full agent conversation, stored in git history.
Why this matters: Agent-generated code without context is a review nightmare. Preserving the reasoning behind changes solves a real pain point for teams scaling AI-assisted development.
Shannon: Open Source AI Pentester That Ships Exploits
Estimated read time: 5 min

Turning to security for all this AI-generated code, Shannon is an open-source AI pentester that autonomously executes real exploits, including injection attacks and auth bypasses, producing pentester-grade reports with reproducible proof-of-concepts. It achieves 96.15% on the XBOW benchmark.
The takeaway: As AI-generated code increases, automated security testing that goes beyond scanning to actual exploitation becomes essential for maintaining production safety.
Pydantic’s Monty: Secure Python Sandbox for AI Agents
Estimated read time: 4 min
Also addressing agent safety, the Pydantic team built Monty, a minimal Python interpreter written in Rust for running LLM-generated code safely inside AI agents. It starts in under one microsecond, blocks filesystem and network access by default, and lets developers control exactly which host functions are exposed.
What this enables: Safe code execution is a prerequisite for production agents. Sub-microsecond startup with granular permissions makes sandboxing practical, not just theoretical.
NEWS & EDITORIALS
Steve Yegge on Anthropic’s Hive Mind Operating Model
Estimated read time: 31 min
Steve Yegge describes Anthropic as operating via a vibes-driven “hive mind” after conversations with nearly 40 employees. With far more work than people, 90-day max planning cycles, and “Yes, and...” improv culture, Anthropic ships products like Claude Cowork in 10 days from concept.
Why this matters: Whether or not this model scales, understanding how the company behind Claude operates gives context for its product decisions and pace of iteration.
Opus 4.6 vs Codex 5.3: The Post-Benchmark Era
Estimated read time: 9 min
Following our coverage of both the Opus 4.6[1] and Codex 5.3[2] launches last week, Nathan Lambert compares the two head-to-head, finding Opus ahead on usability despite narrower capability gaps. While Codex now feels “Claude-like,” Opus requires less detailed instruction and better infers user intent. Lambert’s bigger thesis: traditional benchmarks no longer predict meaningful experience improvements.
[1] Claude Opus 4.6 Arrives with 1M Context Window [2] OpenAI Launches GPT-5.3-Codex
The context: If benchmarks no longer differentiate models, developer experience and workflow integration become the primary selection criteria for your team.
LLMs Have Word Models, Not World Models
Estimated read time: 13 min
Despite all this progress, this essay argues LLMs excel at producing coherent artifacts but fundamentally lack world models for adversarial environments. LLMs produce reasonable-sounding outputs that fail in multi-agent contexts because they cannot simulate how recipients interpret signals.
Key point: Understanding where LLMs genuinely excel (deterministic domains like code) versus where they struggle (negotiation, strategy) helps you deploy them more effectively.
The Hidden Exhaustion Behind AI-Powered Productivity
Estimated read time: 16 min

And for the humans navigating all of this, continuing our coverage of the human cost explored in last week’s “I Miss Thinking Hard” essay[1], an AI infrastructure engineer confesses his most productive quarter was also his most draining, exploring the paradox of AI-accelerated burnout. AI reduced production costs but increased coordination, review, and decision-making overhead. He identifies six fatigue patterns and practical countermeasures.
Worth noting: The tools are getting better, but the human bottleneck is real. Recognizing these fatigue patterns early helps you sustain productivity without burning out.