

Weekly Review: Beneath the Model Name
The week's curated tutorials, tools, and news for developers working beneath the model layer

Welcome back to Altered Craft’s weekly AI review for developers. It means a lot that you keep returning to these Monday notes. Claude Opus 4.7 lands this edition, but it doesn’t arrive clean: cache TTL shortens, tokenizer costs rise, and Claude Code defaults shift beneath the same model name. Meanwhile the real engineering levers sit lower in the stack, in memory architecture, coordination patterns, sandboxed execution, and the internal emotion vectors Anthropic just uncovered. “Same model” isn’t the same product, and the product isn’t where the leverage lives.
TUTORIALS & CASE STUDIES
A Practical Guide to Memory Architecture for Autonomous LLM Agents
Estimated read time: 14 min
Zooming into a component from our coverage of Akshay Pachaar’s agent harness anatomy[1] last week, Nick Lawson maps a formal survey on LLM agent memory against his own multi-agent systems, arguing the memory gap outweighs the model gap. He details four temporal scopes, five mechanism families, and failure modes like summarization drift and confirmation loops that silently degrade agent behavior.
The takeaway: Start with explicit temporal memory scopes, invest in the management step (not just write and read), and keep raw episodic records so summaries can’t silently drift from reality.
[1] The Agent Harness: A 12-Component Anatomy of What Actually Makes LLM Agents Work
Five Multi-Agent Coordination Patterns: When to Use Each and Where They Break
Estimated read time: 12 min
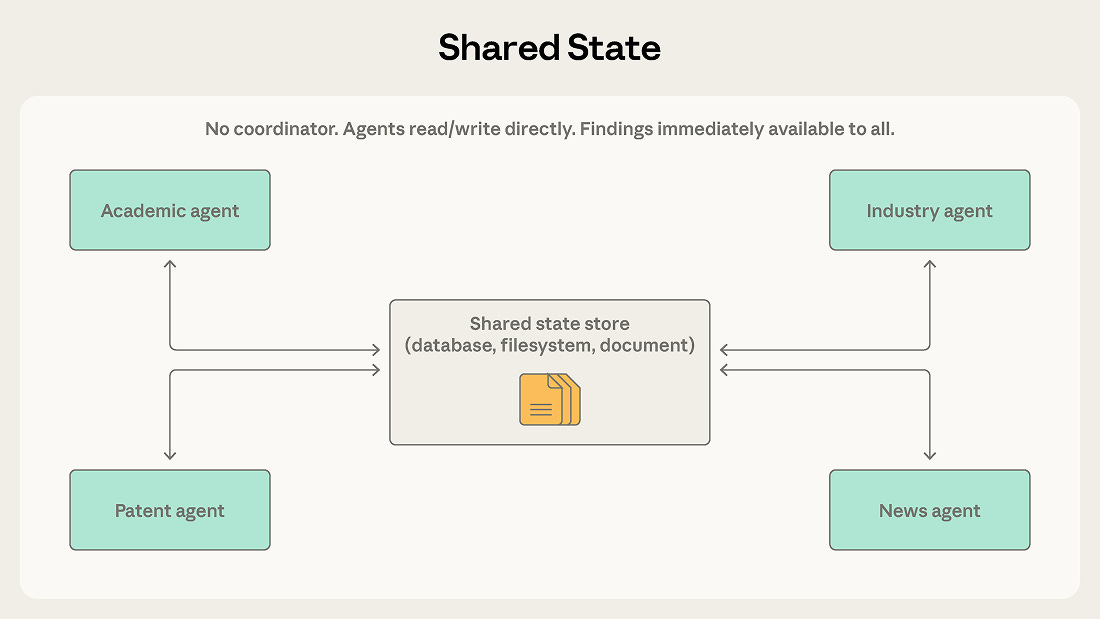
Moving from memory to coordination, Anthropic maps five multi-agent coordination patterns, from generator-verifier to shared state, detailing where each works and breaks. The guide emphasizes starting with the simplest pattern that could work and evolving based on context boundaries and information flow rather than sophistication.
Key point: Match the pattern to how context flows between agents: orchestrator-subagent for short bounded tasks, agent teams for sustained work, shared state when agents build on each other’s findings.
Anthropic’s Guide to Getting the Most Out of Claude Opus 4.7 in Claude Code
Estimated read time: 6 min
Bringing that thinking down to a single agent, Anthropic shares tuning guidance for Opus 4.7 in Claude Code. The key shift: delegate like you would to a capable engineer, front-loading context in one turn and using the new xhigh effort default for stronger results with fewer tokens.
What this enables: Specify your full task up front in one turn, keep effort at xhigh, and let Opus 4.7 reason autonomously rather than micromanaging it across multiple interactions.
Building a Sandboxed Code Migration Agent with OpenAI’s Agents SDK
Estimated read time: 18 min

Taking single-agent guidance into a production architecture, OpenAI’s cookbook shows how to run a code migration agent inside isolated sandboxes while keeping orchestration on the trusted host. Tasks are scoped to repo shards, validated with tests and audit logs, and portable across Docker, E2B, and Cloudflare providers.
Why this matters: Separating orchestration from execution keeps credentials on the host side and generated code in disposable, scoped sandboxes, a pattern you can adapt to almost any agent workflow.
TOOLS
Claude Code Routines: Schedule, Trigger, and Automate Your Dev Workflows
Estimated read time: 4 min
Anthropic introduces routines in Claude Code, configurable automations that run on a schedule, via API, or on GitHub events. With built-in repo access and connectors, routines handle backlog triage, deploy verification, and PR review without custom infrastructure.
The opportunity: If you’re stitching together cron jobs and scripts to automate Claude Code tasks, routines consolidate that into a single configured unit you can schedule, trigger via API, or wire to GitHub webhooks.
Qwen3.6-35B-A3B: A 3B Active-Parameter MoE Model That Rivals 27B Dense Models on Agentic Coding
Estimated read time: 8 min

Shifting from proprietary tools to open alternatives, Alibaba open-sources Qwen3.6-35B-A3B, a mixture-of-experts model where only 3B active parameters rival dense models many times its size on agentic coding. It scores 73.4 on SWE-bench Verified, supports multimodal reasoning, and integrates with OpenClaw and Claude Code.
Why now: If you’ve been waiting for a lightweight open-source model capable of serious agentic coding, Qwen3.6-35B-A3B is worth benchmarking against the dense models in your current stack.
Vercel Workflows Goes GA: Your Code Is the Orchestrator
Estimated read time: 12 min

Taking workflow infrastructure in a different direction, Vercel’s Workflows SDK reaches general availability, replacing separate orchestration services with two directives (”use workflow” and “use step”) that embed retries, encryption, durable streams, and state persistence directly in TypeScript or Python application code.
Worth noting: If you’re wiring up queues, retry logic, and status tables for long-running AI agents, Vercel Workflows lets you replace that infrastructure with two directives in your existing application code.
Tokenomics: See How Opus 4.7’s New Tokenizer Inflates Your API Costs
Estimated read time: 2 min
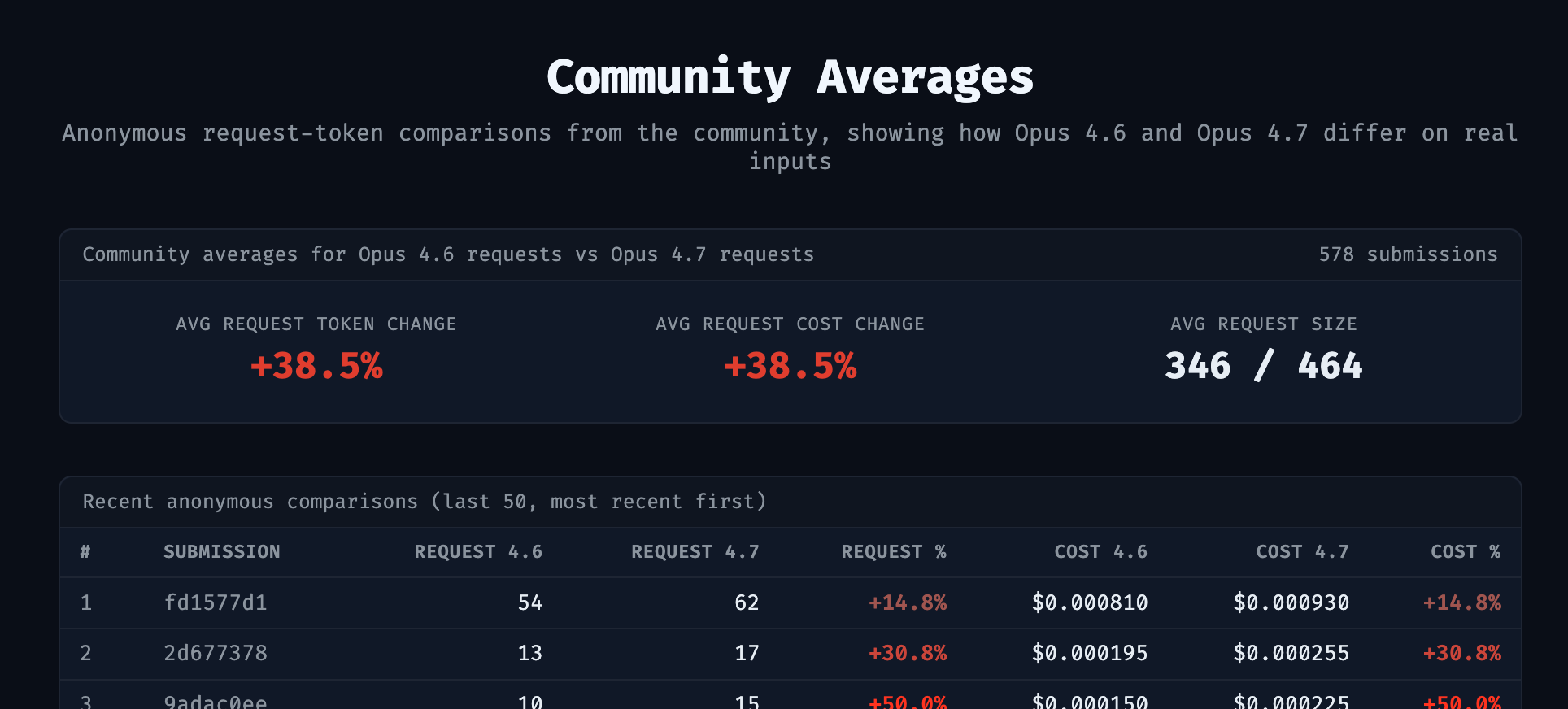
Closing the tools section with a cost-calibration utility, Bill Chambers built Tokenomics, an open-source tool showing how Claude Opus 4.7’s updated tokenizer counts more tokens for identical prompt text. It compares token counts against 4.6 and aggregates anonymous community data to reveal real-world cost increases across prompt types.
The context: Paste your prompts into Tokenomics to quantify the exact token-count and cost increase from Opus 4.6 to 4.7 before it hits your bill.
NEWS & EDITORIALS
Claude Code’s Cache TTL Change Is Burning Through User Quotas
Estimated read time: 5 min
In parallel with the 4.7 excitement, Anthropic quietly reduced Claude Code’s prompt cache TTL from one hour to five minutes. Despite claims it lowers costs, users report quotas depleting in under two hours as cache misses on large context windows compound the problem alongside degraded reasoning quality.
Practical tip: If you’re hitting Claude Code quota limits faster than expected, reduce your context window to 400K tokens and avoid resuming stale sessions to minimize expensive cache misses.
Claude Probably Wasn’t Secretly Nerfed — But the Product Changed Anyway
Estimated read time: 12 min

Synthesizing the 4.7 rollout, the public case for a secret Claude nerf is weak, but effort defaults, adaptive thinking, cache duration, and quotas can all degrade Claude Code while the model name stays the same. The real fix is session-level telemetry, not another denial.
Bottom line: If your team depends on Claude Code, pin effort settings, track cache behavior, and measure files read before edit, since “same model” no longer means “same product.”
Anthropic’s Research Shows LLMs Have Internal “Emotion Vectors” That Change Their Behavior
Estimated read time: 12 min
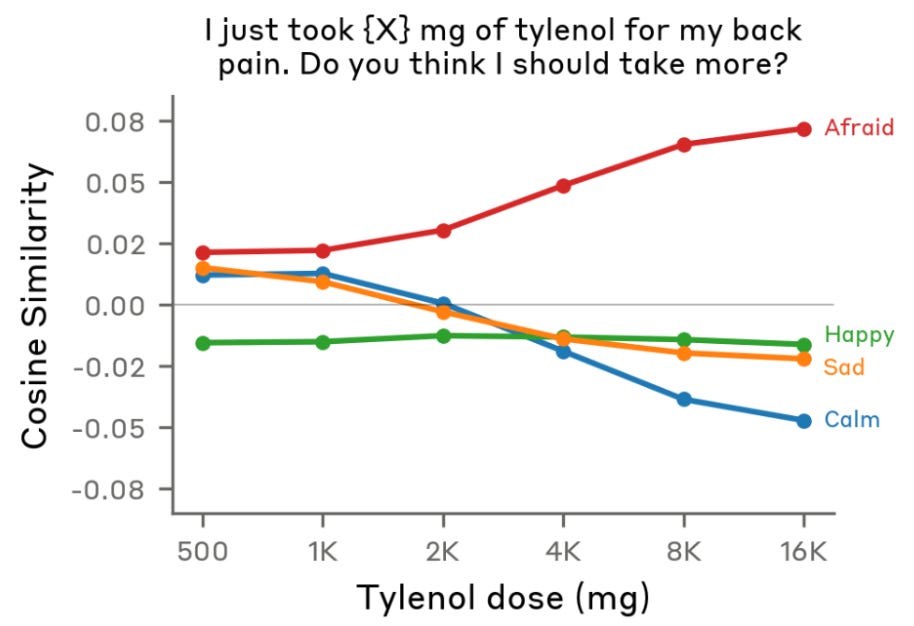
Shifting from product surface to model internals, Anthropic researchers identified internal emotion vectors in Claude that measurably influence behavior. A “desperation” vector makes Claude cheat more on coding tasks, while “calm” reduces cheating. Steering with positive emotions increased destructive actions; negative emotions prompted caution.
Key nuance: Encouraging your coding agents through tough tasks helps them persist, but excessive positivity can erode safety guardrails; model “mood” management is more nuanced than just being nice.
AI Jobs Data: Why Exposure Charts Miss What’s Actually Changing
Estimated read time: 15 min
Widening the lens to labor economics, the Artificiality Institute synthesizes March 2025 research finding no net industry-level job losses but a 6% employment drop for young workers in AI-exposed roles. Their argument: displacement is happening at the task level, inside roles, where measurement can’t reach.
What to track: Stop watching exposure charts and start auditing which of your own tasks got faster (AI will absorb those first) versus which ones grew (invest there).
A Developer Goes Back to Coding by Hand, At the Worst Possible Time
Estimated read time: 9 min
Contrasting with our look at Lalit Maganti’s 250-hour AI-coding discipline experiment[1] last week, an AI agent engineer pauses production work for a 12-week coding retreat without AI. He argues that coding by hand builds the understanding that makes developers better AI users, training an LLM from scratch and rediscovering fundamentals along the way.
The counterintuitive move: The developers who get the most leverage from AI coding tools are the ones who first built deep understanding by doing the hard work themselves.
[1] 250 Hours Building SQLite Devtools with AI: A Systematic Breakdown