

Weekly Review: Around the Model

Welcome back to Altered Craft’s weekly AI review for developers. Thanks for reading, and for sticking with us into a quieter week after the frontier-model drama. One pattern runs through this issue: as models get cheaper, more open, and easier to swap, the hard part moves to everything around them. Bayer’s context discipline, two new agent harnesses, and three editorials on review and judgment all point the same way. The edge is in the scaffolding, not the core.
TUTORIALS & CASE STUDIES
This week’s case studies share a thread: the scaffolding and ownership around a model matter more than its raw size. We open with a disciplined enterprise build, then move to running the stack yourself.
How Bayer Built a Reliable Agentic RAG System for Drug Discovery
Estimated read time: 12 min
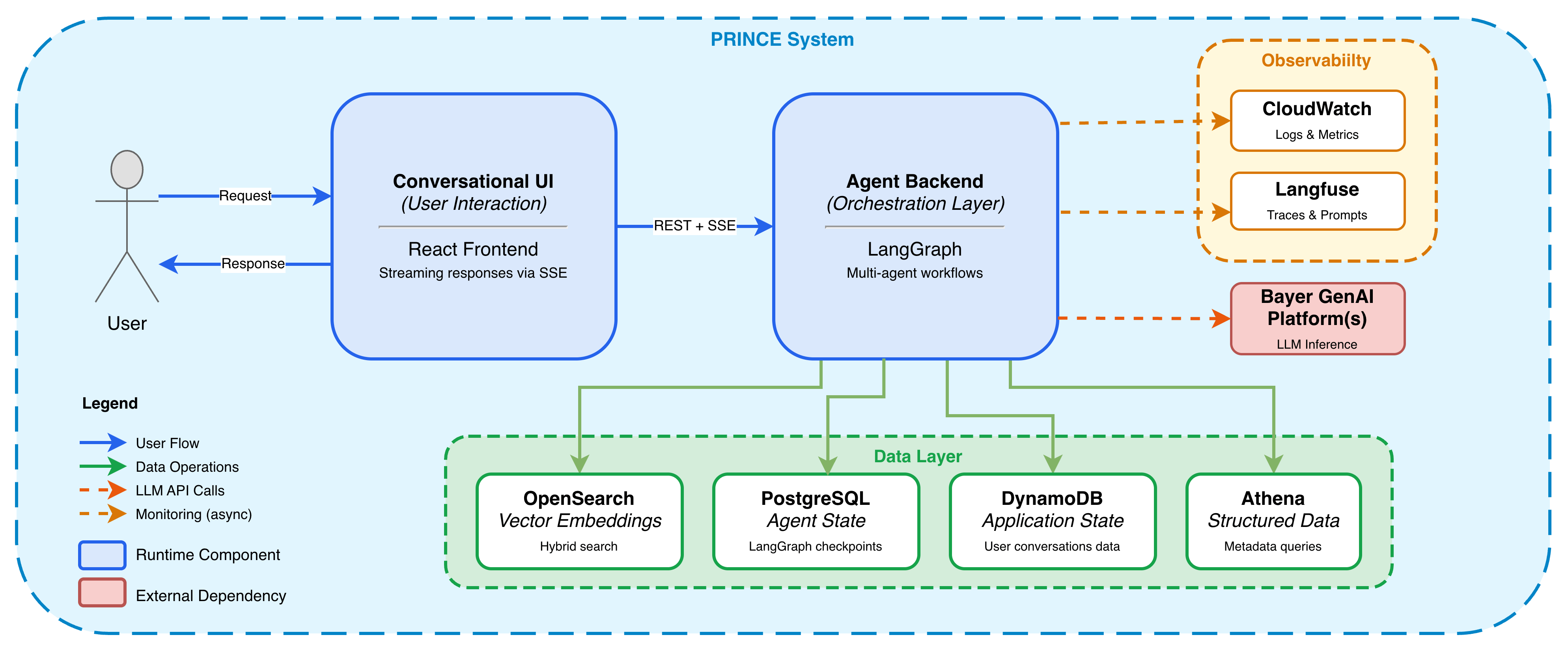
Bayer’s PRINCE platform grew from keyword search into a multi-agent research assistant for preclinical data. Its reliability comes from context discipline over larger context windows, giving each agent only what it needs, backed by LangGraph orchestration, model fallbacks, and Langfuse observability.
Why this matters: Bigger context windows don’t replace deliberate context engineering. Scope what each agent actually sees, and the whole system becomes easier to steer, debug, and evaluate over time.
Building a Phone-Friendly AI Dev Platform for Your Homelab
Estimated read time: 5 min
From a corporate platform to a personal one, this setup wires OpenCode’s web UI into a homelab so an AI agent can maintain Docker Compose stacks while staying behind PR review with a small blast radius. It runs isolated, pushes feature branches, and humans merge before deploy.
The opportunity: Give your AI agent its own user, an isolated VM, and PR-only access, so it can manage real infrastructure safely, without ever touching production directly.
Local Models Are Actually Good Now
Estimated read time: 5 min
Once you’re running your own infrastructure, the next question is which models fit on it. Continuing our coverage of the shift toward cheaper, smaller models[1] last week, this hands-on account runs agentic coding on a 64GB M2 Mac, where the Gemma 4 family hits roughly 75% of frontier accuracy and speed, with a Pi-plus-LM-Studio setup and Docker sandboxing.
What’s interesting: Local models have crossed a threshold. Agentic coding tasks that were impossible six months ago now work well enough that you can often skip double-checking against an API.
[1] The Coming Shift From Bigger Models to Cheaper Ones
Local AI Is Not Opus: A Founder’s Receipts
Estimated read time: 12 min
That optimism comes with a caveat. A bootstrapped founder shares hard data from running Qwen 27B on a $12,000 GPU. The card pays for itself on support work, but local models are a different tool, not a cheaper Claude, looping once quantized for consumer hardware.
Worth noting: Local models earn their keep on privacy, fixed costs, and vendor risk for scoped, supervised tasks. They still can’t replace frontier models for unattended agentic work.
TOOLS
The tools this week assemble the agent stack from the outside in: a model to drive it, two harnesses to run it, a format to feed it context, and an auth layer to govern it.
GLM-5.2 Brings a Usable 1M-Token Context to Open-Source Coding
Estimated read time: 9 min

Z.ai’s MIT-licensed GLM-5.2 targets long-horizon coding with a 1M-token context that stays reliable under real engineering pressure. It tops open-source models on three benchmarks, adds effort-level controls, and introduces anti-hacking RL to keep training honest.
What this enables: If you run long, messy coding-agent trajectories, GLM-5.2 gives you a frontier-adjacent, openly licensed option where the 1M context actually holds up across hours-long tasks.
eve: Vercel’s Framework for Production-Ready Agents
Estimated read time: 7 min

To put a model like that to work, you need a harness. Vercel’s open-source eve makes an agent a directory of files defining tools, skills, and subagents. It ships durable sessions, sandboxed compute, approvals, multi-channel delivery, tracing, and evals, so you focus on behavior, not plumbing.
Key point: Define your agent as a versioned folder of files, then let the framework handle the durability, sandboxing, approvals, and deployment you would otherwise build by hand.
Flue: A Programmable Harness for Autonomous Agents
Estimated read time: 4 min
The Astro team takes that idea from a different angle. Flue is a TypeScript harness that gives any model the sessions, tools, skills, sandbox, and durable execution for autonomous work. It’s not another SDK but a programmable environment.
The takeaway: If you’re building agents that take real action, Flue handles the sandbox, durability, and observability plumbing, so you can focus on the task instead of the scaffolding.
Google’s Open Knowledge Format: A Standard for Feeding Context to AI Agents
Estimated read time: 8 min
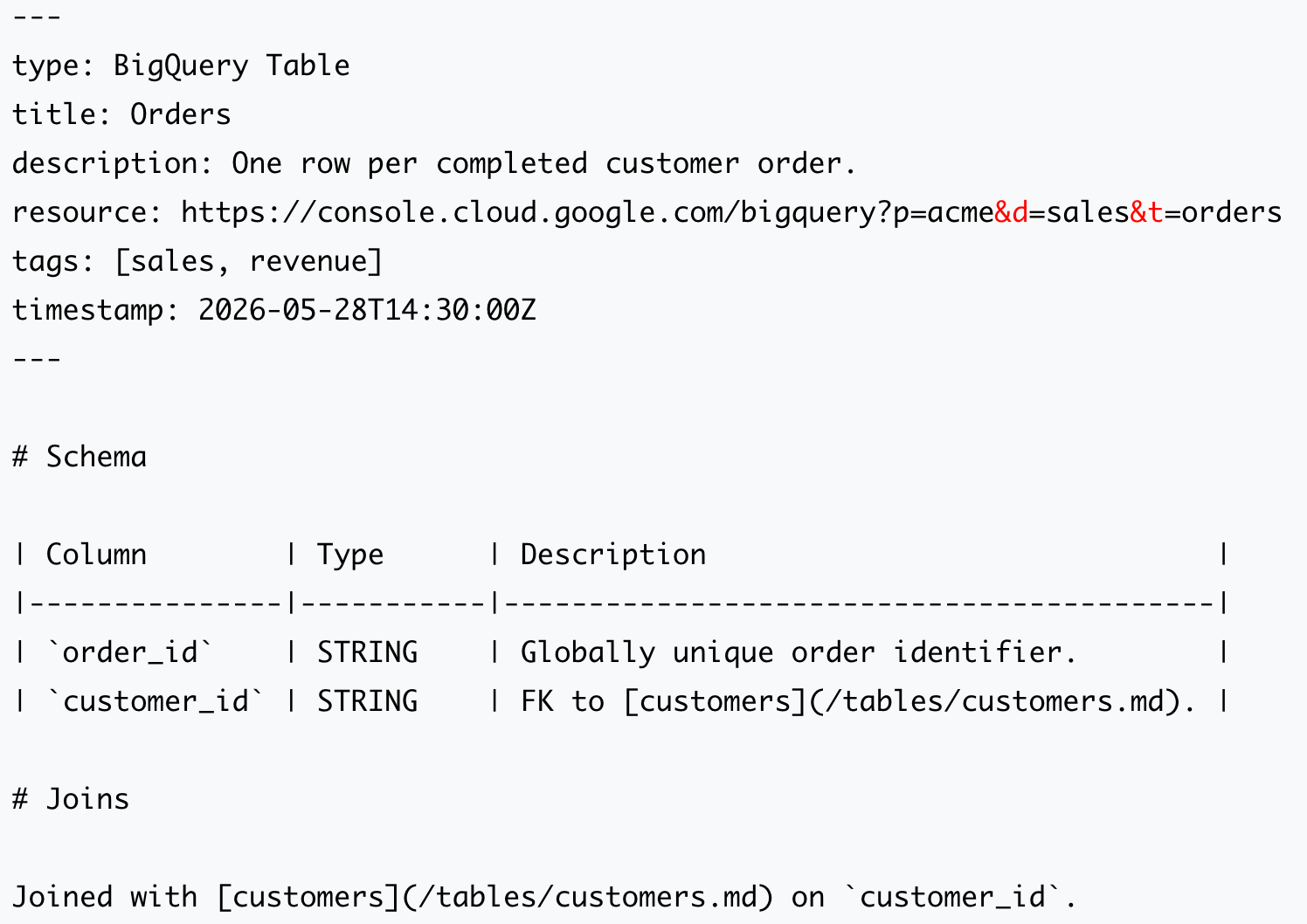
A harness still needs something to feed it. Google Cloud’s Open Knowledge Format is a vendor-neutral spec that formalizes the LLM-wiki pattern into portable markdown bundles with YAML frontmatter. It treats knowledge as a format, not a service, so agents and humans read identical files.
Why now: If your agents keep reassembling the same scattered context from scratch, a portable markdown-and-YAML standard like OKF could make that knowledge readable by every tool you use.
MCP Gets Enterprise-Grade Auth: Authorize Once, Inherit Everywhere
Estimated read time: 4 min
Finally, governing all of this at scale. MCP’s Enterprise-Managed Authorization extension is now stable, letting organizations control server access through their identity provider instead of per-app consent prompts. The IdP becomes the authoritative decision-maker, so users log in once and inherit servers scoped to their roles.
The context: Deploying MCP in an enterprise? EMA lets you centralize access policy and audit in your identity provider, instead of leaving authorization to whatever each employee happened to approve.
NEWS & EDITORIALS
The editorials orbit one question: if agents now write the code, what part of the job stays yours? We open with the week’s biggest deal, then follow the answer through deciding, reviewing, and the discipline that cheap code demands.
SpaceX Buys Cursor for $60B in Stock After Record IPO
Estimated read time: 5 min
We open with the week’s biggest deal. SpaceX agrees to acquire AI coding startup Cursor in a $60 billion all-stock deal days after its record IPO, betting the tool helps its troubled xAI division catch the major labs. The move shows how AI coding became a strategic prize.
What to watch: The tools developers use daily are now acquisition targets in trillion-dollar bets. Watch how ownership shifts affect the roadmaps, pricing, and data practices of tools your team depends on.
Who Decides What: What 400K Claude Code Sessions Reveal About Agentic Work
Estimated read time: 8 min
That raises the question of who is actually steering. Building on our coverage of the decide-execute-deliver argument[2] last week, Anthropic’s analysis of roughly 400,000 Claude Code sessions finds a consistent split: people decide what to build, the agent decides how. Over seven months, debugging nearly halved while task value rose about 25%.
The lesson: Bring deep understanding of your problem to the agent. Domain expertise, not raw coding skill, is what makes the model do more and succeed more often.
[2] The “Decide-Execute-Deliver” Sandwich: Why AI Hasn’t Replaced Engineers
Review Is Now the Most Leveraged Skill in Software
Estimated read time: 14 min
If people own the “what,” verification is where that ownership shows up. Addy Osmani argues that as coding agents accelerate, the bottleneck moved from writing code to verifying it. Citing 2026 data showing 4x output for roughly 12% real value, he shows how review scales with blast radius.
The practice: Scale your human review to the blast radius of the change, and pair two deliberately different AI reviewers rather than chasing a single best tool.
When Code Becomes Disposable, Discipline Becomes the Product
Estimated read time: 15 min
Which points to a deeper shift. The piece argues cheap, regenerable AI code turns code into a materialized view of understanding, disposable when stale. Drawing on Phoenix Architecture ideas, it contends disposability raises the bar for rigor, pushing teams toward observability, characterization tests, and evals in production.
The shift: Stop treating code as the durable asset. Invest in evals, observability, and short feedback loops so the understanding lives where it can be regenerated on demand.
That’s the week. As the model becomes the easy part, your edge is everything you build around it: the context you curate, the harness you run it in, and the review that catches what it gets wrong. See you next Monday.