

Weekly Review: Around the Model
The week's curated tutorials, tools, and news for developers building the structures wrapped around AI models

Welcome to Altered Craft’s weekly AI review for developers, and thanks for spending part of your Monday with us. One thread runs through this edition: the engineering leverage in AI keeps moving outward, away from the model itself and into the harness wrapped around it. A source-level read of Claude Code finds 98.4% of the codebase isn’t AI, Anthropic’s own postmortem ties a month of regressions to small infra changes, and pieces on AGENTS.md, skills, evals, and multi-agent patterns all push the same direction.
TUTORIALS & CASE STUDIES
What Actually Makes an AGENTS.md File Work
Estimated read time: 9 min
Augment Code measured dozens of AGENTS.md files and found a quality gap equivalent to upgrading from Haiku to Opus. Progressive disclosure, decision tables, and pairing every “don’t” with a “do” win. Sprawling overviews and warning-heavy docs trigger context rot.
The takeaway: Keep AGENTS.md to 100-150 lines of focused guidance with reference files loaded on demand, and pair every prohibition with a concrete alternative.
Skillify: Turning Agent Failures Into Permanent Fixes
Estimated read time: 11 min
Taking agent reliability further, Garry Tan argues most AI agent reliability work is “vibes-based” prompt tweaking that decays under complexity. His answer: skillify, a 10-step practice that promotes every failure into durable infrastructure with deterministic scripts, tests, LLM evals, and resolver routing audits.
Why this matters: When your agent fails, don’t apologize-prompt it; turn the failure into a skill with deterministic code and tests so the bug becomes structurally impossible to repeat.
The AI Evaluation Stack: Beyond Vibe Checks for Production LLMs
Estimated read time: 10 min
Moving from preventing failures to detecting them, Microsoft’s Derah Onuorah lays out a two-layer evaluation architecture for enterprise LLMs: deterministic schema asserts first, LLM-as-a-Judge second. The piece details offline golden datasets and online telemetry tracking refusal rates, retries, and apology patterns to catch silent model drift.
What this enables: Treat evaluation as a CI/CD-gated pipeline with fail-fast deterministic checks before expensive semantic scoring, then instrument production for the behavioral signals that reveal silent drift.
The Over-Editing Problem: When AI Coding Tools Rewrite Too Much
Estimated read time: 9 min

Drilling into a specific failure mode evaluation should catch, this investigation measures how often frontier LLMs rewrite more than a bug fix requires, a brown-field failure invisible to test suites. Benchmarking 9 models, the author finds reasoning modes amplify over-editing, but explicit prompting and targeted fine-tuning yield faithful, minimal edits.
Worth trying: Adding “preserve the original code as much as possible” to your prompt measurably shrinks AI-generated diffs and often improves correctness too.
Using a Local LLM as a Zero-Shot Classifier
Estimated read time: 9 min

Stepping outside coding workflows, when clustering fails on short, paraphrase-heavy text, a locally hosted LLM steps in as a zero-shot classifier that understands meaning. The author walks through an Ollama pipeline that turns thousands of free-text annotations into a clean taxonomy without labels.
The opportunity: When you have domain knowledge but no labels, define categories upfront and let a local LLM handle the classification without a training cycle.
TOOLS
GPT-5.5 Lands: Agentic Coding, Computer Use, and Research Workflows Level Up
Estimated read time: 9 min
OpenAI releases GPT-5.5 as a step toward agentic work that plans, uses tools, and persists through ambiguity. It hits 82.7% on Terminal-Bench 2.0, 78.7% on OSWorld-Verified, and uses fewer tokens than GPT-5.4 while matching its latency.
What’s interesting: For engineers delegating multi-step work to agents, GPT-5.5’s token efficiency and long-horizon focus are worth testing against your current Codex and Cursor workflows.
Kimi K2.6: Open-Source Model Ships with Agent Swarms and Long-Horizon Coding
Estimated read time: 12 min
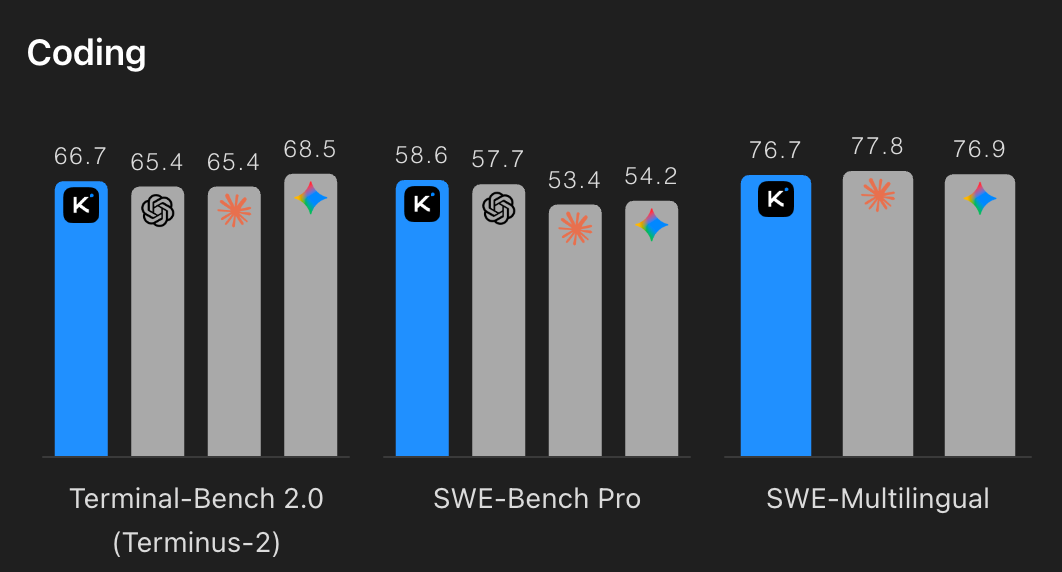
On the open-source side of that release wave, Moonshot AI ships Kimi K2.6, featuring agent swarms scaling to 300 sub-agents across 4,000 coordinated steps. It sustains 12+ hour autonomous coding sessions and benchmarks competitively against GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro on agentic tasks.
Worth evaluating: If you’re building agentic coding workflows, K2.6’s open-source availability and competitive benchmarks against frontier closed-source models make it a real option for long-running autonomous tasks.
DeepSeek-V4 Lands With 1M Context as Default
Estimated read time: 3 min
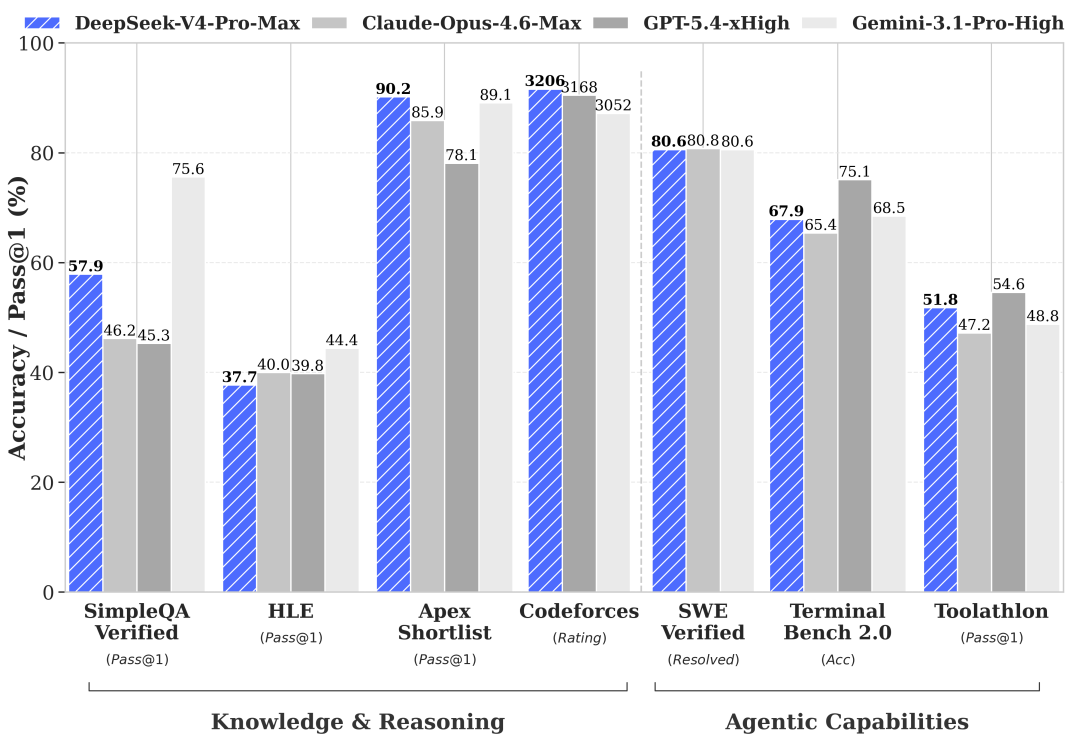
Continuing the open-weights momentum, DeepSeek released V4-Pro and V4-Flash, with 1M context now standard across all services. The release introduces DeepSeek Sparse Attention for efficiency, claims SOTA on agentic coding among open models, and supports both OpenAI and Anthropic API formats.
Worth noting: With OpenAI and Anthropic API compatibility, V4-Flash slots in as a lower-cost drop-in alternative worth benchmarking against your current provider on real workloads.
Gemini Embedding 2 Hits General Availability with Native Multimodal Support
Estimated read time: 1 min
Shifting from generation to retrieval, Google announces general availability of Gemini Embedding 2 via the Gemini API and Vertex AI. The model produces native embeddings across text, image, video, and audio, eliminating fragmented pipelines multimodal search previously required. Preview-phase prototypes can now move to production.
Why now: If you’ve been waiting to ship multimodal search or retrieval features, Gemini Embedding 2 is now production-ready on both the Gemini API and Vertex AI.
NEWS & EDITORIALS
Inside Claude Code: 98.4% of the Codebase Isn’t AI
Estimated read time: 18 min

A source-level analysis of Claude Code’s ~512K lines reveals only 1.6% is AI decision logic. The rest is deterministic infrastructure: permission gates, context compaction, and recovery systems. The repo maps seven safety layers with shared failure modes and distills findings into actionable agent-building guidance.
Where to invest: If you’re building AI agents, put your engineering effort into the harness — permission systems, context management, and recovery logic — not the model loop itself.
Anthropic’s Postmortem on Claude Code Degradation
Estimated read time: 9 min
Following our coverage of the Claude Code degradation debate[1] last week, Anthropic’s postmortem now traces a month of regressions to three overlapping changes in reasoning defaults, cache eviction, and system prompts. The issues compounded across traffic slices, evading internal evals, tests, and dogfooding until user reports surfaced them.
Key point: When AI-coding tools start feeling “off,” trust the pattern in user reports, since small prompt and caching tweaks can quietly erode quality in ways evals miss.
[1] Claude Probably Wasn’t Secretly Nerfed — But the Product Changed Anyway
Five Coordination Patterns for Multi-Agent Systems
Estimated read time: 12 min
Zooming out from a single agent harness to multi-agent design, Anthropic breaks down five multi-agent coordination patterns, examining where each shines and where each breaks. The piece argues for starting with the simplest pattern that could work and evolving as constraints appear, rather than reaching for sophistication teams mistake for real capability.
The decision rule: Choose your multi-agent pattern based on context boundaries and information flow, not on what sounds impressive in a design doc.
The Hidden Cost Curve Behind AI Agent Progress
Estimated read time: 9 min
Zooming further out to the economics of running these systems, Toby Ord examines METR’s time-horizon benchmarks and asks a question few are: how is the hourly cost of AI agents changing over time? Analyzing performance-versus-cost curves, he finds hourly costs rising exponentially, with frontier models approaching human engineer rates.
The context: Headline AI capability trends may overstate practical progress, so plan deployments around sweet-spot costs on the curve, not peak frontier performance.