

Weekly Review: Agents, Autonomy, and the Humans in Between
This week's essential AI tutorials, tools, and industry perspectives for developers

Thanks for joining another edition of Altered Craft’s weekly AI review for developers. Your readership keeps this community growing, and we appreciate it. This week’s collection spans a fascinating range: from Stripe merging 1,300 agent-written PRs weekly to a solo developer building a personal agent in 2,000 lines of Go. Meanwhile, two major model releases landed in the same week, and a strong set of editorials makes the case that human expertise is not just surviving the AI era but gaining value.
TUTORIALS & CASE STUDIES
Advanced Prompt Caching Strategies for OpenAI APIs
Estimated read time: 8 min
Extending our coverage of Nicolas Bustamante’s thirteen token cost strategies[1] from last week, OpenAI’s advanced guide reveals techniques for cutting LLM latency by 80% and costs by 90% through prompt caching. Learn to stabilize prefixes, use the prompt_cache_key parameter, and leverage allowed_tools to preserve caches across tool variations. One customer jumped from 60% to 87% hit rates.
[1] Thirteen Strategies to Cut Your LLM Token Costs
The opportunity: If you’re running agent systems or RAG pipelines with repeated system prompts, these caching patterns can dramatically reduce your API bill and response latency with minimal code changes.
How Stripe Merges 1,300 Agent-Written PRs Weekly
Estimated read time: 9 min
Shifting from API optimization to agent infrastructure, Stripe’s Minions merge over 1,300 pull requests weekly using autonomous coding agents on isolated EC2 devboxes. Part 2 details their hybrid blueprint orchestration combining deterministic and agentic nodes, their Toolshed MCP server with 500 internal tools, and their feedback-shifting approach.
Why this matters: The blueprint pattern of mixing deterministic steps with agentic decisions is emerging as a key design principle. Stripe’s investment in MCP tooling and isolated environments offers a replicable architecture.
From Prototype to Production AI Agents on AWS
Estimated read time: 5 min

For teams building their own agent infrastructure, this AWS reference architecture walks through four progressive iterations for deploying AI agents using Amazon Bedrock AgentCore Runtime. Each stage adds production layers: API Gateway for rate limiting, Lambda with IAM for security isolation, and DynamoDB for conversation persistence.
What this enables: You can start with a browser-to-agent prototype and progressively adopt production layers like IAM isolation and conversation persistence as your system matures. A great learning scaffold.
Building Effective AI Agents Without the Complexity
Estimated read time: 6 min
Taking a radically different approach to agent complexity, Justin Abrahms built epiphyte, a 2,000-line Go agent as an alternative to the 600K+ line OpenClaw. The formula: cron plus LLM plus a scratch pad. Using flat-file storage, git auto-commits, and lightweight kernel sandboxing instead of Docker.
Key point: As agent frameworks balloon in complexity, this is a refreshing reminder that useful personal agents can be built with familiar tools and a few hundred lines of code.
Agent Frameworks Have a Systemic Security Problem
Estimated read time: 7 min
Whether you choose complex or simple agent architectures, security remains the critical gap. This analysis argues that OpenClaw’s issues reveal a systemic architectural flaw across all agent frameworks, identifying five control gaps: inadequate runtime isolation, overprivileged credentials, insufficient tool restrictions, poor observability, and unvetted plugins.
The takeaway: The five control gaps listed here make a practical security checklist for anyone deploying agents. Review your own architecture against them before shipping to production.
TOOLS
Claude Sonnet 4.6: Preferred Over Opus for Coding
Estimated read time: 7 min

Reinforcing our discussion of Nathan Lambert’s post-benchmark thesis[1] from last week, Anthropic’s Claude Sonnet 4.6 arrives with a 1M token context window and a surprising real-world result: users preferred it over Opus 4.5 in 59% of coding comparisons, citing better instruction-following and less overengineering. Pricing stays at $3/$15 per million tokens.
[1] Opus 4.6 vs Codex 5.3: The Post-Benchmark Era
What’s interesting: A smaller, cheaper model outperforming the flagship on real coding tasks suggests model selection should be driven by task fit and workflow needs, not tier assumptions or sticker price.
Gemini 3.1 Pro Doubles Reasoning Performance on ARC-AGI-2
Estimated read time: 4 min
Following our look at Google’s Gemini 3 Deep Think[1] last week, Google’s Gemini 3.1 Pro now brings a major reasoning upgrade to the general-purpose line, scoring 77.1% on ARC-AGI-2. More than double its predecessor’s performance. Available through Google AI Studio, Gemini CLI, Vertex AI, and the new Antigravity agentic platform.
[1] Gemini 3 Deep Think Sets New Reasoning Records
Worth noting: Two major model releases in one week underscores how fast the reasoning bar is rising. Developers building model-agnostic architectures are best positioned to capitalize on this competitive pressure.
Run Parallel Claude Code Sessions with Worktrees
Estimated read time: 5 min
Back in the Claude ecosystem, Claude Code now supports parallel development sessions through git worktrees with a simple --worktree flag. Each session gets its own isolated branch and working directory while sharing repository history. Subagents can also use worktree isolation for parallel work.
The context: As AI coding sessions grow longer and more autonomous, parallel isolated workflows become essential. This feature lets you run multiple agent tasks on a single repo without merge conflicts.
Claude Pilot: Production-Grade AI Development Framework
Estimated read time: 6 min

Building on Claude Code’s worktree support, Claude Pilot wraps Claude Code in a production-grade framework with 15 lifecycle hooks across six events. The /spec command drives a structured workflow: plan, implement in isolated worktrees, then verify with independent review agents. Automated hooks enforce TDD and dispatch linters after every edit.
Worth watching: The gap between “Claude Code can write code” and “Claude Code reliably ships production code” is largely about guardrails. This project offers a concrete answer.
Let AI Agents Organize Themselves with Cord
Estimated read time: 6 min
Shifting from individual agent sessions to multi-agent coordination, Cord introduces a protocol where AI agents autonomously organize into task hierarchies at runtime. Built in roughly 500 lines of Python with SQLite and MCP, it uses two primitives: spawn (clean context) and fork (inherited context).
The appeal: A lightweight alternative to framework-heavy multi-agent systems. The spawn/fork protocol is simple enough to learn in an afternoon and flexible enough to handle real decomposition problems.
Simon Willison’s Tool for Reproducible Code Demos
Estimated read time: 4 min
On the developer tooling front, Simon Willison’s Showboat is a Go CLI that turns markdown documents into executable, verifiable demos. Write narrative text alongside code blocks that actually run, capture outputs, and later re-execute everything to confirm results remain consistent. Supports multiple languages and image embedding.
Practical use: Perfect for documenting AI-assisted coding workflows where you need to prove outputs are reproducible. Think demo scripts, tutorials, and onboarding materials that verify themselves on every run.
NEWS & EDITORIALS
ThoughtWorks Retreat: Software Practices Breaking Under AI
Estimated read time: 4 min
Martin Fowler shares takeaways from the ThoughtWorks Software Development Retreat, where industry leaders concluded that practices built for human-only development are breaking. LLM refactoring performs 30% better on healthy codebases, and TDD has emerged as essential for AI-assisted coding. A detailed summary is also available.
Why now: When ThoughtWorks luminaries say nobody has it figured out yet, it’s both validating and motivating. The 30% code quality correlation is a concrete reason to invest in clean architecture today.
Why AI Makes Domain Experts More Valuable
Estimated read time: 12 min

Reinforcing the retreat’s emphasis on human skill, Philipp Dubach presents evidence that domain expertise is appreciating rather than depreciating alongside AI advances. A 53-point gap persists between AI and human experts on Humanity’s Last Exam, and Harvard research confirms AI amplifies existing skill levels rather than replacing them.
Career signal: The data consistently shows that deep domain knowledge compounds your effectiveness with AI tools. Investing in your craft and maintaining hands-on expertise remains the highest-leverage career move available.
AI as Exoskeleton: Amplifying Rather Than Replacing Developers
Estimated read time: 9 min
Similarly advocating for human-centered AI, Ben Gregory argues developers should treat AI as an exoskeleton that amplifies capability rather than an autonomous replacement. The article advocates decomposing workflows into discrete, AI-assisted tasks instead of replacing entire roles. Preserved cognitive capacity compounds when developers focus on creative problem-solving.
Design principle: The exoskeleton framing offers a practical guideline: build single-purpose AI tools for specific tasks rather than monolithic agents that attempt to handle entire workflows autonomously.
Why Your Team’s AI Usage Doesn’t Equal Adoption
Estimated read time: 8 min
But reframing AI doesn’t eliminate organizational friction. Industry data reveals a paradox: 40% of employees believe in AI’s value while fearing personal consequences, driving usage that reflects self-protection rather than genuine adoption. High-anxiety employees use AI for 65% of tasks yet report double the resistance to embracing it.
For team leads: If you’re leading a team through AI adoption, the distinction between usage and genuine engagement is critical. The four employee archetypes offer a useful framework for identifying where your team members stand.
How Agent Autonomy Evolves in Real-World Use
Estimated read time: 30 min
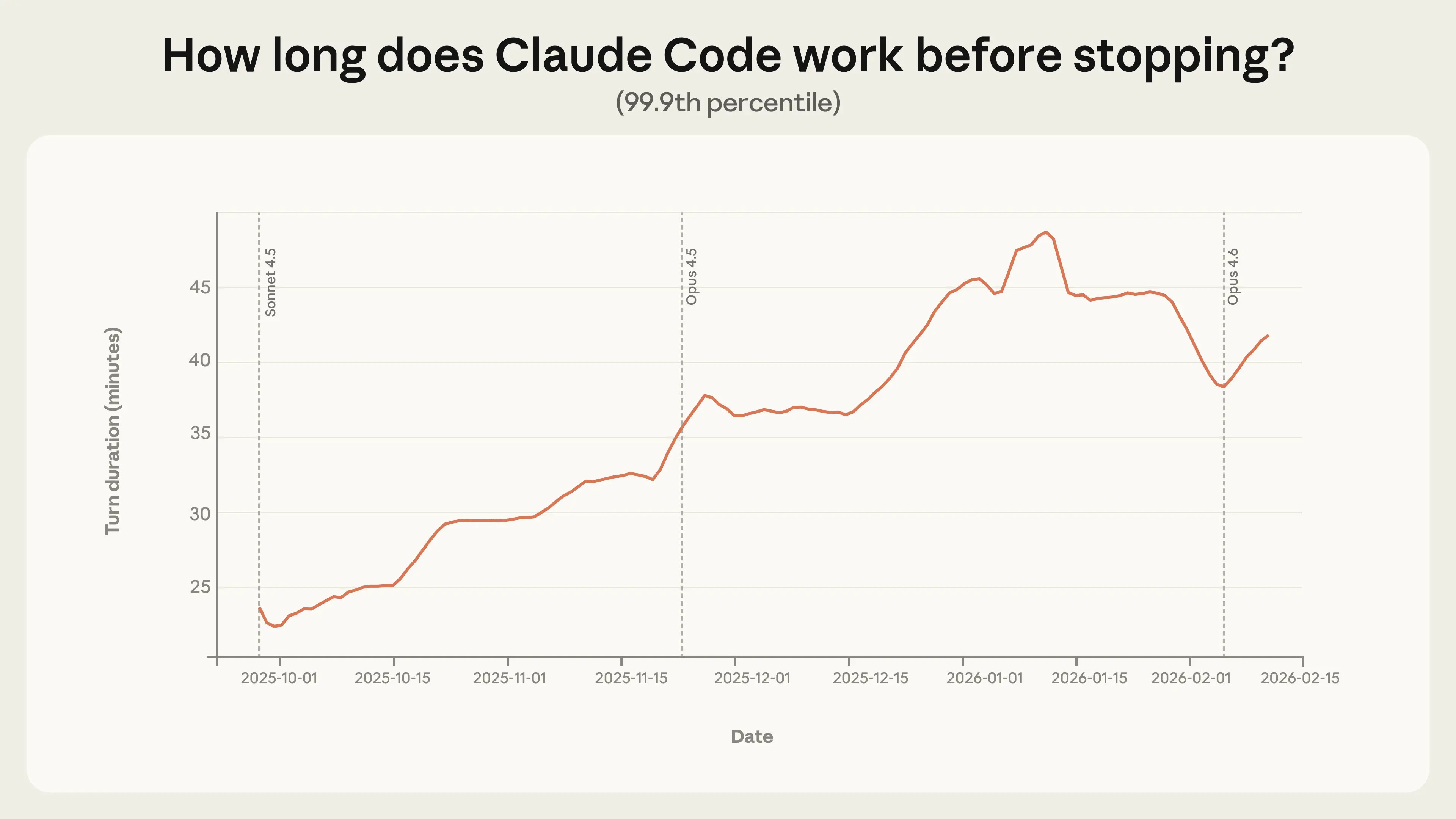
While organizations wrestle with human adoption, agents themselves are gaining independence. Anthropic analyzed millions of interactions and found that Claude Code sessions nearly doubled their autonomous operating time over three months, reaching 45+ minutes. Agents ask clarifying questions more than twice as often as humans interrupt them.
The shift: The finding that agents self-regulate better than humans interrupt suggests we may be over-supervising. Experienced users are already shifting to monitoring-based oversight, trusting the model’s own uncertainty signals.
The Security Case Against Autonomous Email Agents
Estimated read time: 5 min

Grounding these autonomy trends in a specific risk, Martin Fowler warns that LLM email agents embody Simon Willison’s Lethal Trifecta: untrusted content, sensitive data, and external communication in a single system. Password-reset workflows pass through email, creating account takeover vectors. Fowler suggests sandboxing with read-only access and no internet connectivity.
Worth considering: Before connecting an LLM to your inbox, the Lethal Trifecta framework provides a clear mental model for evaluating whether your agent deployment crosses from useful into dangerous territory.