

Weekly Review: Agent Internals and the Developer's Evolving Role
The week's curated set of relevant AI Tutorials, Tools, and News

Thanks for joining Altered Craft’s weekly AI review for developers. Your continued readership means a lot to us. This edition pulls back the curtain on how agents actually work, with OpenAI detailing Codex internals and practical MCP design patterns from Philipp Schmid. Meanwhile, several thought-provoking pieces ask what developers should focus on as agents handle more execution. Whether you’re optimizing agent architecture or reflecting on your own evolving role, there’s something here for you.
TUTORIALS & CASE STUDIES
OpenAI Unpacks the Codex Agent Loop Architecture

Estimated read time: 12 min
OpenAI details how the Codex CLI orchestrates user, model, and tool interaction. The agent loop handles context window management while supporting local Ollama and LM Studio endpoints. Components include model-specific instructions, shell and planning tools, plus MCP integrations.
Why this matters: Understanding agent loop internals helps you debug unexpected behavior, optimize token usage, and build more reliable agent systems of your own.
Code-Only Agents Force Computational Work Into Verifiable Form
Estimated read time: 6 min
This architecture constrains agents to code execution only. Instead of natural language, agents produce executable code witnesses demonstrating the solution. This eliminates hallucinations by grounding work in runtime semantics. A Claude Code plugin is available for experimentation.
The takeaway: When you need verifiable, auditable agent work, forcing output through code execution provides guarantees that natural language responses simply cannot offer.
Six Best Practices for Designing MCP Tools
Estimated read time: 7 min
Continuing our coverage of his MCP CLI work on dynamic tool discovery[1] from last week, Philipp Schmid argues MCP is a user interface for AI agents, not infrastructure. Key recommendations: design tools around agent goals, use flat primitives over nested dictionaries, limit servers to 5-15 tools, and prefix names like slack_send_message for discoverability.
[1] MCP CLI Slashes Context Window Consumption by 99%
What this enables: If you’re building MCP servers, these patterns prevent the common mistake of exposing raw APIs that agents struggle to use effectively.
Running Claude Code Safely with VM Isolation
Estimated read time: 6 min
Taking a local approach compared to our coverage of Fly.io’s Sprites cloud sandboxing[1] last week, this guide shows how to use Claude Code with --dangerously-skip-permissions safely by isolating it in a Vagrant-managed VirtualBox VM. The setup provides full isolation with synced folders and quick startup. Claude can then manage databases and run tests without constant permission prompts.
[1] Fly.io Launches Sprites for Sandboxed AI Agent Development
The opportunity: Get the productivity benefits of autonomous agent execution without the anxiety of running unsandboxed on your main development machine.
Filesystem Tools vs Vector Search for Document Retrieval
Estimated read time: 8 min
LlamaIndex benchmarked agentic file search against traditional RAG. Filesystem tools achieved higher correctness (8.4 vs 6.4) and relevance (9.6 vs 8.0) but slower speed. RAG dominates for large datasets and real-time apps; agentic search suits smaller sets where quality trumps latency.
Key point: Your retrieval architecture choice now depends on dataset size and latency requirements. Neither approach universally wins, so match the method to your constraints.
Production Monitoring Beats Traditional Evals for AI Systems
Estimated read time: 5 min
Raindrop’s CTO argues production monitoring reveals more truth than predefined eval sets for AI products. With personalized experiences for millions of users, traditional evals become insufficient. He recommends minimal smoke-testing followed by rapid deployment with semantic pattern detection.
Why now: As AI systems become more personalized and generative, the industry is recognizing that real-world monitoring catches issues that static test suites miss entirely.

TOOLS
Awesome Claude Aggregates Developer Resources and Tools
Estimated read time: 4 min

A curated directory of Claude AI tools and resources. Find SDKs across Python, TypeScript, Java, Go, and more, IDE plugins, MCP server implementations, and 100+ community-built agents. Includes Discord communities and official training courses on API development.
Worth noting: Before building your own Claude integration, check here first. Someone may have already solved your specific use case or shared useful patterns.
Claude Code Upgrades Todos to Tasks for Complex Project Tracking
Estimated read time: 2 min
Claude Code transitions from “Todos” to a Tasks system for complicated projects across multiple sessions or subagents. This enables better project continuity and work delegation across longer workflows.
What this enables: Multi-session projects that previously lost context between conversations can now maintain state and coordinate subagents more reliably.
Vercel Launches Skills CLI for Cross-Platform Agent Packages
Estimated read time: 3 min
Vercel releases a CLI for managing skill packages across Claude Code, Copilot, Cursor, and other agents. Run npx skills add <package> to enhance agents with reusable capabilities. The skills.sh marketplace provides discovery across the ecosystem.
The context: Agent skills are becoming portable across platforms. This standardization means your investment in learning one agent’s capabilities transfers to others.
Cursor Shares How Bugbot Doubled Resolved Bugs Per Pull Request
Estimated read time: 10 min

Cursor’s AI code review agent processes over 2 million PRs monthly. Key technique: majority voting across parallel bug-finding passes with randomized diff ordering. After 40 experiments, resolution rate improved from 52% to over 70%. Aggressive prompting outperformed restrictive approaches.
What’s interesting: The counterintuitive finding that aggressive prompting beats restrictive approaches challenges common assumptions about constraining AI behavior.
GLM-4.7-Flash Delivers Strong Performance in 30B Parameter Class
Estimated read time: 5 min
Z.ai releases a 30B MoE model with 131K context under MIT license. Benchmarks: 91.6 on AIME 25, 59.2 on SWE-bench Verified (vs Qwen3’s 22.0). Features preserved thinking mode for agentic work. Deploy via vLLM, SGLang, or Transformers.
The opportunity: An MIT-licensed model competitive on coding benchmarks gives you a strong self-hosted option for agent workflows without API costs or vendor lock-in.
Kaggle Launches Community Benchmarks for Custom AI Evaluations
Estimated read time: 3 min
Kaggle now lets users build, share, and run custom evaluation frameworks for AI models. Design assessments specific to your use cases and leverage community-created tools. This democratizes AI evaluation beyond standard benchmarks.
Why this matters: Standard benchmarks rarely match your production requirements. Custom evals let you measure what actually matters for your specific application.
PersonaPlex Enables Full-Duplex Conversational AI with Persona Control
Estimated read time: 7 min
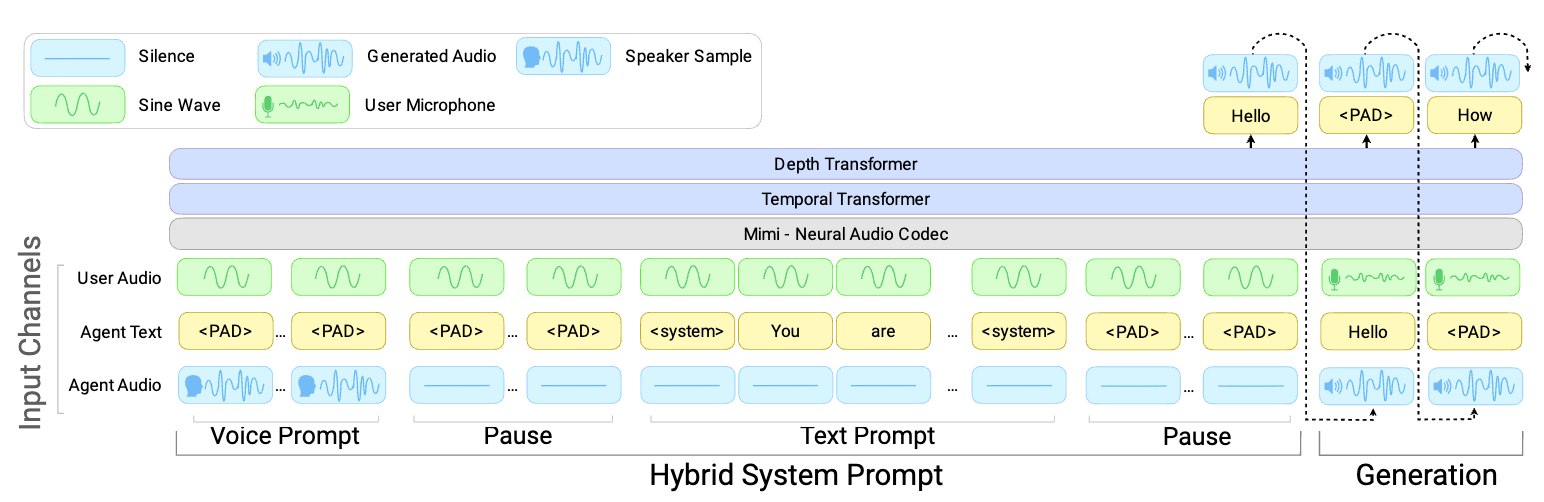
NVIDIA’s 7B system listens and speaks simultaneously, eliminating awkward pauses in voice AI. Define behavior through hybrid prompting combining voice and text-based role descriptions. Demonstrates emergent generalization to scenarios with technical terminology never seen during training.
Worth noting: Full-duplex voice AI that maintains persona consistency opens new possibilities for natural conversational interfaces in developer tools and user-facing applications.
NEWS & EDITORIALS
Cursor Team Says the IDE Is Dead, Agents Write the Code Now
Estimated read time: 10 min
Cursor’s team declares manual coding now comprises as little as 10% of some workflows. Focus has shifted to directing agents and reviewing output. Their research team built a browser using agents, generating 3 million lines at $80,000 in token costs.
The context: Whether or not you agree with “IDE is dead,” the data point of 3M lines for $80K signals where we’re headed. The economics of agent-driven development are becoming viable.
Strategic Delegation Replaces Grinding as the Key Agent Skill
Estimated read time: 8 min
Agent technology pushes humans up the organizational hierarchy. Rather than grinding through implementation, focus on cultivating clarity to guide agents effectively. Lambert’s workflow combines GPT for planning, Claude Code for implementation, with agents running in parallel under oversight.
Key point: The skill of translating fuzzy requirements into clear agent direction is becoming more valuable than raw coding speed. Worth practicing deliberately.
Communication Now Trumps Coding as the Critical Engineering Skill
Estimated read time: 4 min
With AI agents handling execution, software engineering has become fundamentally a people problem. Key competencies: clarifying requirements through probing questions, facilitating trade-off discussions, exercising judgment on unspecified details. The bottleneck has shifted from implementation to specification.
The takeaway: Technical skills remain important, but the developers advancing fastest are those who excel at extracting clear requirements from ambiguous situations.
Why Some Developers Will Never Love AI Coding Tools
Estimated read time: 5 min
Stephen Brennan distinguishes “product-focused” from “process-focused” developers. He values the intrinsic reward of creating and understanding code, not just output. For those who enjoy representing problems in code, AI automates the part they actually value.
What’s interesting: This honest counterpoint helps clarify your own relationship with AI tools. Knowing whether you’re product or process-focused shapes how you integrate them.
LLMs as Thinking Tools: Articulating What You Already Know
Estimated read time: 4 min
LLMs often articulate things we understand but cannot clearly express. As developers, we build tacit understanding that never becomes explicit. LLMs turn vague structure into language, making implicit assumptions visible. This feedback loop improves internal reasoning over time.
The opportunity: Use LLMs not just for code generation, but as thinking partners that help surface and refine the design intuitions you’ve built through experience.
Meta Superintelligence Labs Delivers First Internal Models
Estimated read time: 4 min

Meta’s new Superintelligence Labs team has delivered first high-profile AI models internally just six months in. Text model “Avocado” and multimodal “Mango” are in development. CTO Bosworth says 2026-2027 will see consumer AI trends firm up.
Why now: Meta’s accelerated timeline and new lab structure signals intensifying competition. Watch for how their open-source strategy evolves with these new models.