

The Steering Tax
Why the most capable model is often the cheapest path to working code

I’ve always defaulted to the top-tier model from whatever lab I’m using. Anthropic, Google, OpenAI. Not out of any special insight. It just felt like the right trade. Lately I’ve been trying to articulate why.
A note on terminology: every frontier lab structures their lineup differently, but for this piece I’ll use prime to mean the most capable model available (Opus 4.5, GPT-5.2, Gemini 3) and secondary for the next tier down, whether that’s a smaller variant or a previous generation. The distinction matters more than the specific names.
The pattern I keep seeing: developers three corrections deep, context filling with failed attempts, each response worse than the last. They’re not coding anymore. They’re stuck in an endless loop of re-prompting and reviewing. The secondary model is costing them hours.
The industry benchmarks measure token generation speed. But in agentic coding, the real cost isn’t generation. It’s steering. The human time spent course-correcting, re-prompting, recovering from false starts. That’s the tax. And it compounds.
For novel work, I want the prime model as orchestrator. Let the tooling (Claude Code, Cursor, whatever harness you’re using) decide when to delegate subtasks to secondary models. But the intelligence at the top of the decision tree should be the best available.
My sense is that the December 2025 generation of prime models widened the capability gap enough to change the calculus for more developers. As early as 2024, Simon Willison described this as crossing “an invisible capability line.” Whether that’s a true inflection point or just my experience, I can’t say for certain. But the ROI case has never been easier to make.
What Steering Actually Costs
The obvious cost is time. Reading the output, diagnosing the problem, crafting a correction, waiting for the next attempt. Every course correction burns attention.
But there’s a second cost that’s easier to miss: context pollution. Every failed attempt stays in your conversation history. Every “actually, let me try again” accumulates. This creates a feedback loop. The longer the conversation runs, the more likely you are to hit context rot. Chroma’s research shows that model performance degrades as context length increases, especially for information in the middle of the window. Your context isn’t just limited. It actively degrades when you fill it with steering artifacts.
Factory.ai notes that effective context capacity is typically 60-70% of the advertised maximum. If you’re burning that limited resource on failed attempts, you’re making every subsequent response worse.
This reframes the calculation:
Total time = one-shot generation + steering + correction generation
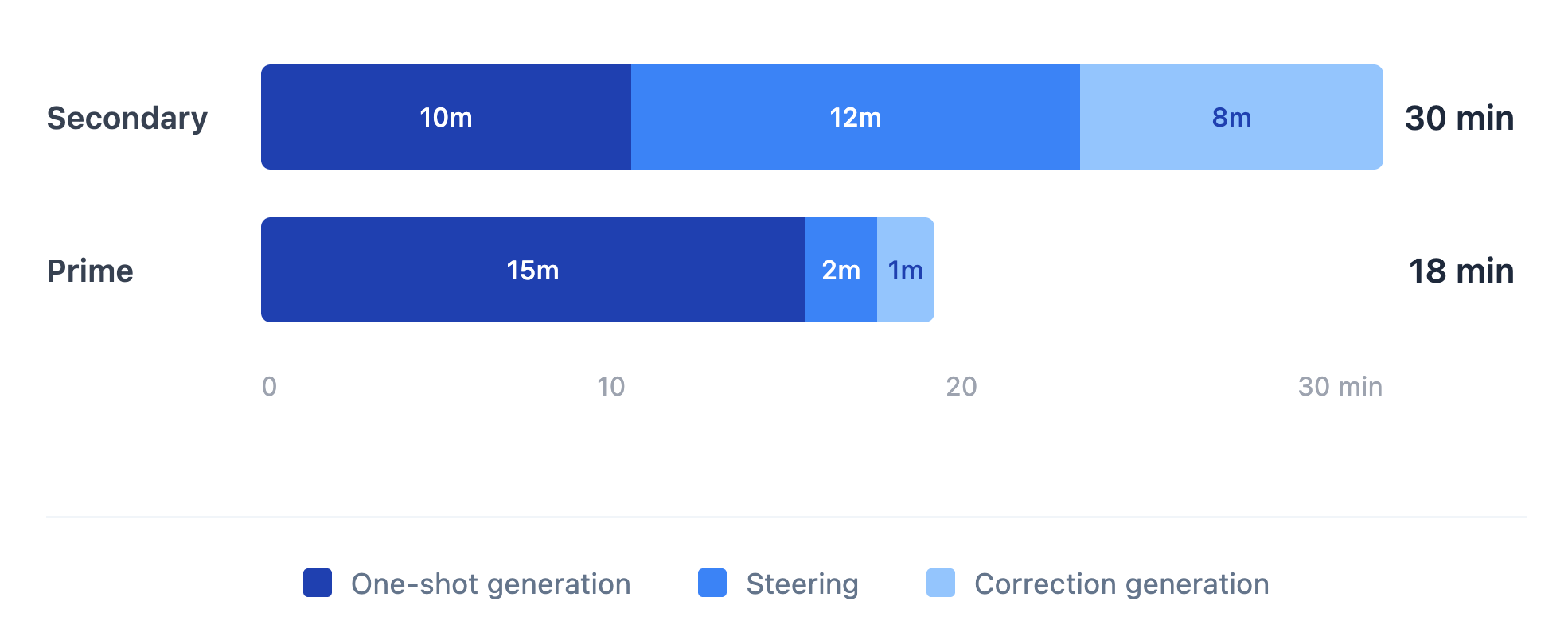
Secondary models minimize the first term. That’s what the benchmarks measure. But if they maximize the other two, you haven’t saved time. You’ve traded cheap compute for expensive human attention. That’s a net loss.
What Practitioners Are Actually Doing
The ROI logic holds up beyond my own experience. When Boris Cherny, the creator of Claude Code, revealed his workflow, one detail stood out: he exclusively uses Opus 4.5 with extended thinking, the prime configuration.
His reasoning: “Even though it’s bigger and slower than Sonnet, since you have to steer it less and it’s better at tool use, it is almost always faster than using a smaller model in the end.”
The insight compounds. Less re-prompting means cleaner context. Cleaner context means better subsequent responses. The prime model creates a virtuous cycle that the latency benchmarks completely miss.
Nathan Lambert described this as “a watershed moment, moving software creation from an artisanal, craftsman activity to a true industrial process.” On the Lex Fridman podcast, he put the model selection logic simply: “... for code and any sort of philosophical discussion, I use Claude Opus 4.5. Also always with extended thinking.” For novel work requiring judgment, he wants the best orchestrator available. And he’s willing to pay for it.
This pattern keeps appearing among experienced practitioners. The people shipping the most aren’t optimizing for token cost. They’re optimizing for how far the agent can get without needing them.
Prime for Judgment, Secondary for Chores
I do the bulk of my novel work in Claude Code with the prime model. Coding, yes, but also business strategy, writing, architectural decisions. Anything where judgment matters and a false start would be expensive to recover from.
Secondary models handle the deterministic work. Formatting. Simple bug fixes. Chores where I’ll know immediately if the output is right. When verification is trivial, the cost savings make sense.
I also make a point of testing new secondary releases when they drop, often during intro free-tier windows. Anthropic, for instance, typically targets each new Sonnet to match or exceed the previous Opus. Tracking these capability jumps helps calibrate when a secondary model has crossed the threshold for a given task scope.
Self-Correction in Practice
One example from my own testing: I ran the same task through both Opus and Sonnet. The task had some ambiguity: refactor an educational app to copy a sample ChromaDB to a gitignored location on startup, add helpful terminal output, run tests, update docs. Multi-step, some judgment calls required.
Both models completed the task. Opus took 10 minutes. Sonnet took 30.
The time difference came from steering. Partway through, Opus noticed something it had gotten wrong. The prompt had specified “give helpful terminal output as to the actions of this process.” Opus had placed the new logging code before create_app(), which meant the logger wasn’t initialized yet. Mid-task, it caught the disconnect and moved the code to where logging would actually work.
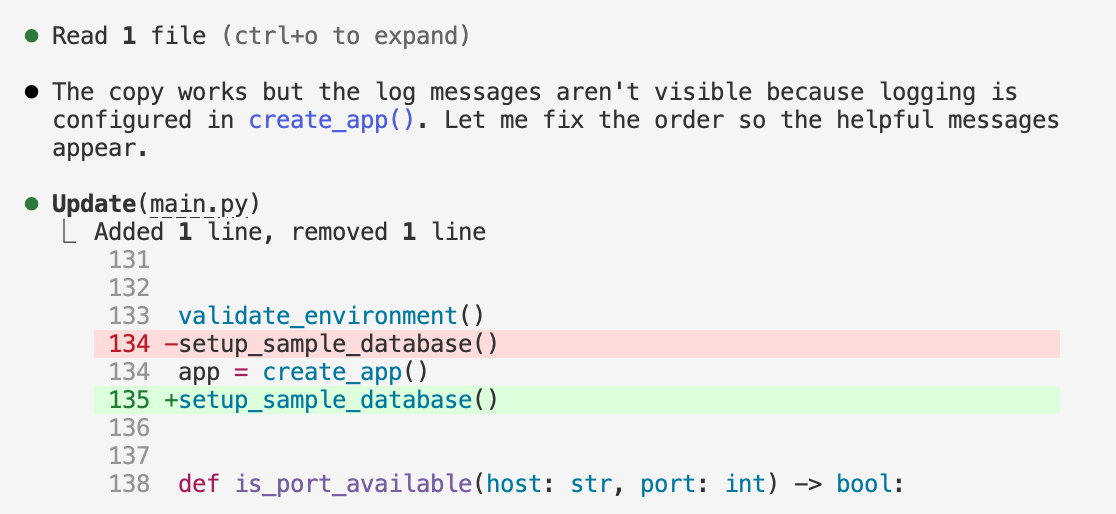
create_app(), so it shifts the new code to meet the logging requirement.Sonnet made the same mistake. It didn’t catch it. I found it in testing, pointed it out, and Sonnet fixed it. But that’s a steering cycle I had to initiate. Context burned. Time lost.
That’s the difference that compounds. Not whether the model is perfect, but whether it catches its own errors before I have to. Every self-correction is a steering intervention I didn’t need to make.
This matters because “almost right” is expensive. The Stack Overflow 2025 survey found that 66% of developers cite “AI solutions that are almost right, but not quite” as their top frustration. Sonar’s 2026 survey adds that 38% say reviewing AI-generated code requires more effort than reviewing human code. Prime models that catch their own near-misses before you have to? That’s where the steering tax gets paid upfront.
The Real Metric
The question I’ve started asking:
Given a clear and detailed specification, how far can this agent get without needing me?
That’s autonomy. That’s what determines whether I can context-switch to something else, or whether I’m stuck in a loop of reviewing and re-prompting a conversation that keeps drifting off course.
Your context may differ. If you’re doing high-volume deterministic work, the calculus changes. If cost is a hard constraint, the tradeoff shifts. But if you’ve been optimizing for token cost and wondering why you’re still course-correcting constantly, try the prime model for a week. Track the steering. Do the math yourself.
My prime models are GPT-5.2 Codex XHigh, Opus 4.5 thinking, Gemini 3 pro, but also Kimi 2 thinking and now Kimi 2.5 for plan reviews or brainstorming. Kimi often find one brillant idea or dig one aspect that was overlooked or missed by the Big 3.
My secondary is GLM 4.7 and it's actually very good. GLM 4.6 was a mid-secondary, 4.7 is a top one.