

Notes from building a tiny long-running agent harness
Twenty cents and a workbench for open-weights models

Notes from building a tiny long-running agent harness
I built Tilth as a workbench: a ~600-line Python agent harness that runs autonomously against any OpenAI-compatible endpoint. I wanted my own mechanism for actually doing work with open-weights models, not just chatting with them, and I wanted to internalize the current thinking on long-running agents while I did it. Addy Osmani’s trilogy on long-running agents is a great treatment of that thinking; read it, it’s what nudged me to build this. This post is a check-in on what I learned doing it.
The architecture, distilled
Three components, independently replaceable:
Brain. A thin wrapper around the
openaiSDK pointed at any OpenAI-compatible base URL. Worker and judge can sit on different providers.Hands. A per-session git worktree, bash + file tools, allow-listed.
Session. An append-only
events.jsonlplus a checkpoint, enough towake(session_id)on a fresh process.
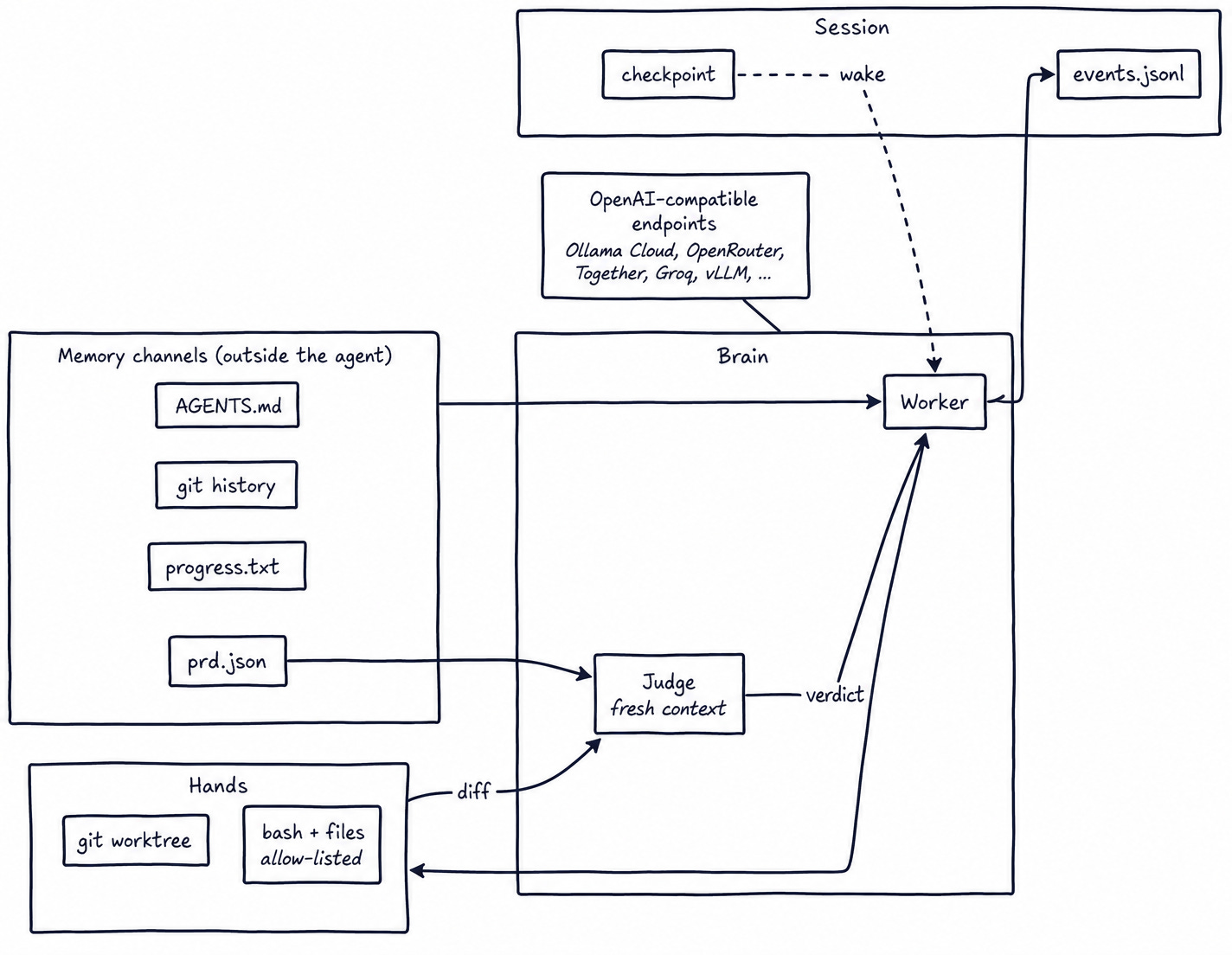
Four memory channels live outside the agent so context resets don’t lose state: AGENTS.md for learned conventions, git history for atomic commits per task, progress.txt as a chronological journal, prd.json as the task list with status flags. Each is a different shape of memory; drop any one and something useful collapses.
A separate judge call evaluates each finished task in a fresh context: diff plus acceptance criteria, nothing else. The adversarial split is load-bearing: don’t let the same session implement and judge. Workers grading their own work wave too much of it through. A different prompt with a clean window is the minimum; a different model family is better.
What I actually learned running it
The judge was the best lens into the worker. Watching the worker chew through a task and then watching a fresh-context judge push back on the result, with no chain-of-thought, no tool history, just the diff, was the most enlightening signal I got. My first judge prompt was too harsh and rejecting reasonable work; tuning it was almost entirely prompt work, no code changes. That felt right. The harness shouldn’t need a redeploy to recalibrate taste.
Open weights are cheap enough not to think about. After multiple end-to-end runs I’d burned five cents on OpenRouter. That’s the cost regime where you stop optimizing prompts for token count and start optimizing for the things you actually care about: clarity, recoverability, watchability.
The provider stops mattering. I started against the native Ollama SDK, then noticed Ollama Cloud also exposes an OpenAI-compatible API endpoint so does basically every other provider. About 60 lines of changes later, the same harness works against Ollama Cloud, OpenRouter, Together, Groq, vLLM, LM Studio, and many more. Worker on one provider, judge on another, different env vars, no other changes. The interesting use isn’t cost. It’s independence. Different model families catch different failure modes; Cursor reported that Opus tended to declare itself done early on extended autonomous runs while GPT held out longer. The same harness lets you put one in the worker seat and the other in the judge seat without rewriting anything.
If you’ve been waiting for a better moment to actually evaluate open-weights models against your own work, this is what cheap-enough looks like. The workbench fits in ~600 lines and a worktree on your laptop.
What this isn’t
Not a managed platform. Not a fleet. Not a multi-agent system. One Ralph loop, a worktree, four files, two hooks, a judge. Some Python glue code.
It’s also not done. This is the kind of thing I expect to keep evolving as a way to poke at open-weights models with something more substantive than a chat window. If that turns out to be useful to anyone else, great. The project’s first job is to be my workbench. The repo is at AlteredCraft/tilth; a ready-to-run example workspace lives at tilth-demo-todo-cli.